
Pablo Samuel Castro
October 26, 2021
The Difficulty of Passive Learning in Deep Reinforcement Learning
We propose the “tandem learning” experimental design, where two RL agents are learning from identical data streams, but only one interacts with the environment to collect the data. We use this experiment design to study the empirical challenges of offline reinforcement learning.
Georg Ostrovski, Pablo Samuel Castro, Will Dabney
This blogpost is a summary of our NeurIPS 2021 paper. We provide two Tandem RL implementations: this one based on the DQN Zoo, and this one based on the Dopamine library.
Introduction
Learning to act in an environment purely from observational data (i.e. with no environment interaction), usually referred to as offline reinforcement learning, has great practical as well as theoretical importance (see this paper for a recent survey). In real-world settings like robotics and healthcare, it is motivated by the ambition to learn from existing datasets and the high cost of environment interaction. Its theoretical appeal is that stationarity of the data distribution allows for more straightforward convergence analysis of learning algorithms. Moreover, decoupling learning from data generation alleviates one of the major difficulties in the empirical analysis of common reinforcement learning agents, allowing the targeted study of learning dynamics in isolation from their effects on behavior.
In this paper we draw inspiration from the experimental paradigm introduced in the classic Held and Hein (1963) experiment in psychology. The experiment involved coupling two young animal subjects’ movements and visual perceptions to ensure that both receive the same stream of visual inputs, while only one can actively shape that stream by directing the pair’s movements. By showing that, despite identical visual experiences, only the actively moving subject acquired adequate visual acuity, the experiment established the importance of active locomotion in learning vision.
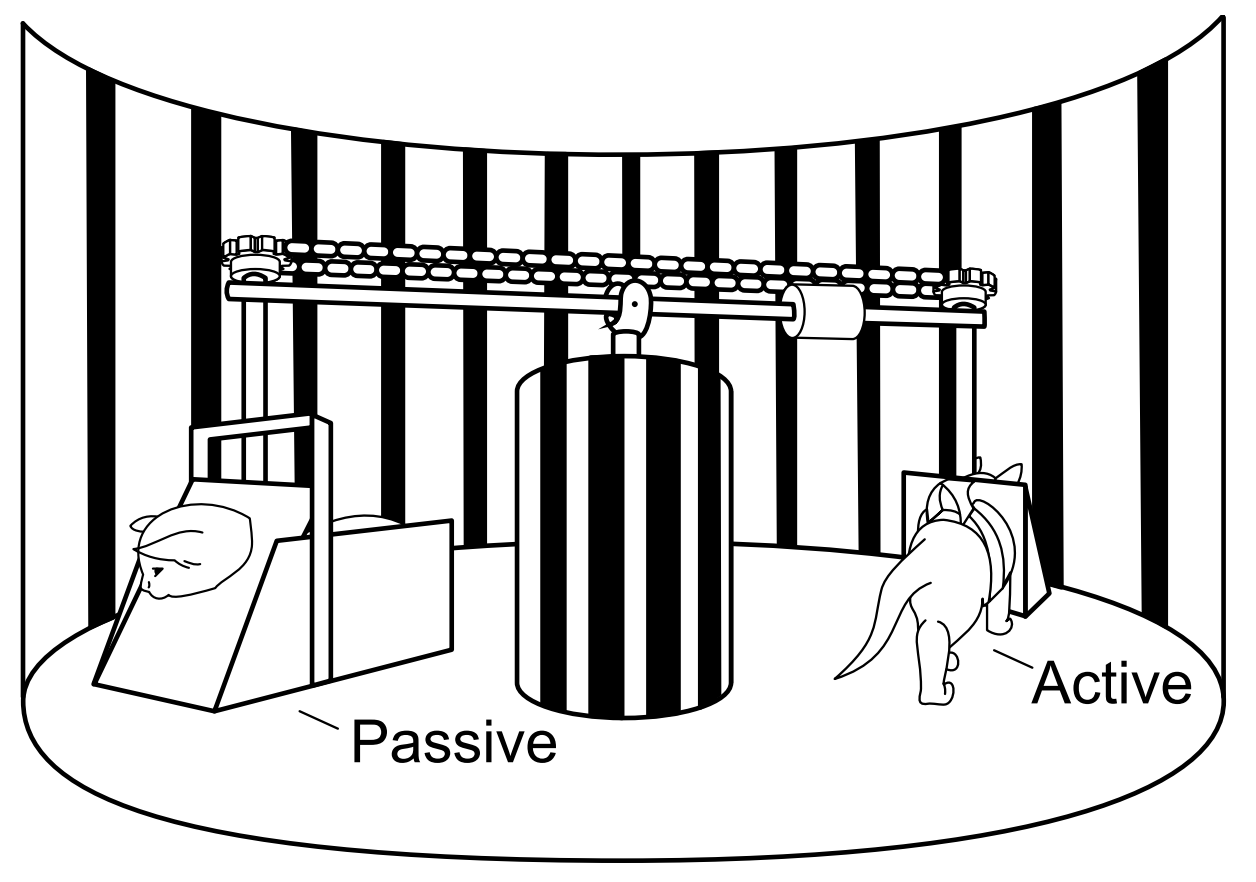
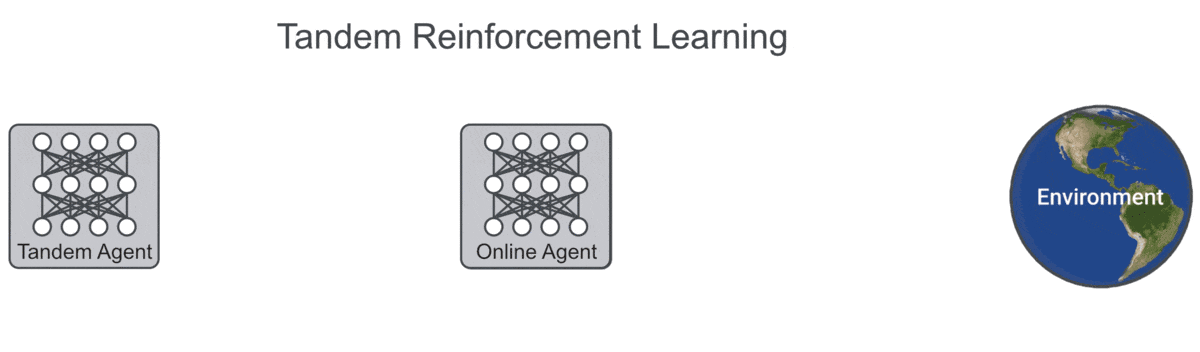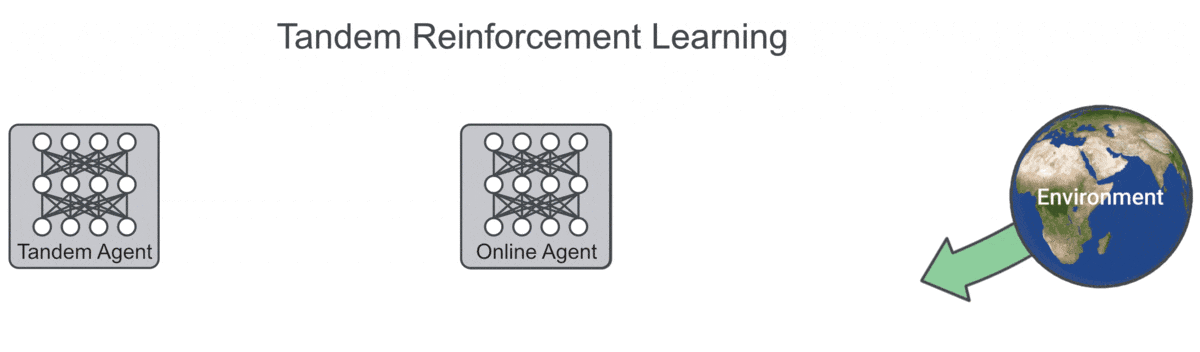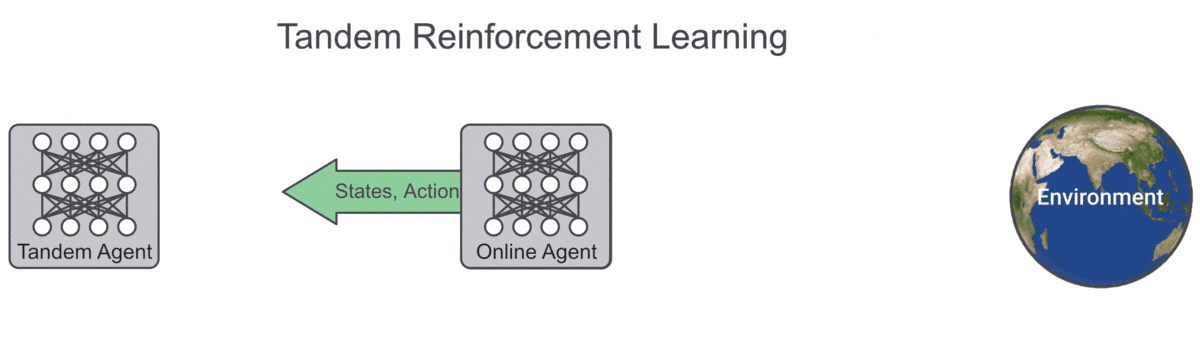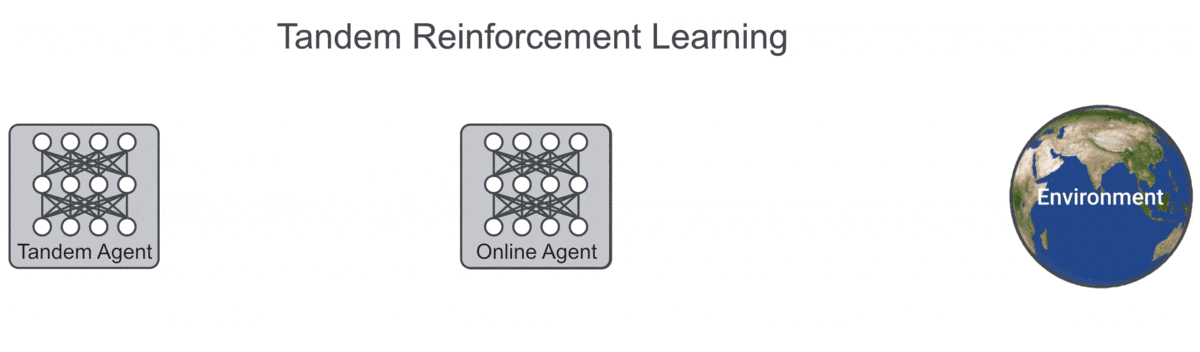
Analogously, we introduce the ‘Tandem RL’ setup, pairing an ‘active’ and a ‘passive’ agent in a training loop where only the active agent drives data generation, while both perform identical learning updates from the generated data . By decoupling learning dynamics from its impact on data generation, while preserving the non-stationarity of the online learning setting, this experimental paradigm promises to be a valuable analytic tool for the precise empirical study of RL algorithms.
Holding architectures, losses, and crucially data distribution equal across the active and passive agents, or varying them in a controlled manner, we perform a detailed empirical analysis of the failure modes of passive (i.e. non-interactive, offline) learning, and pinpoint the contributing factors in properties of the data distribution, function approximation and learning algorithm.
The Experimental Paradigm of Tandem Reinforcement Learning
The Tandem RL setting, extending a similar analytic setup in [Fujimoto et al., 2019], consists of two learning agents, one of which (the ‘active agent’) performs the usual online training loop of interacting with an environment and learning from the generated data, while the other (the ‘passive agent’) learns solely from data generated by the active agent, while only interacting with the environment for evaluation. We distinguish two experimental paradigms:
Tandem: Active and passive agents start with independently initialized networks, and train on an identical sequence of training batches in the exact same order.
Forked Tandem: An agent is trained for a fraction of its total training budget. It is then ‘forked’ into active and passive agents, which start out with identical network weights. The active agent is ‘frozen’, i.e. receives no further training, but continues to generate data from its policy. The passive agent is trained on this generated data for the remainder of the training budget.

Implementation
Our basic experimental agent is ‘Tandem DQN’, an active/passive pair of Double-DQN agents [van Hasselt et al., 2016]. Most of our experiments are performed on the Atari domain, using the exact algorithm and hyperparameters from [van Hasselt et al., 2016]. We use a fixed set of four representative games to demonstrate most of our empirical results, two of which (Breakout, Pong) can be thought of as easy and largely solved by baseline agents, while the others (Seaquest, Space Invaders) have non-trivial learning curves and remain challenging. Unless stated otherwise, all results show averages over at least 5 seeds, with confidence intervals indicating variation over seeds. In comparative plots, boldface entries indicate the default Tandem DQN configuration, and gray lines always correspond to the active agent’s performance.
See the top of the post for links to the source code.
The Tandem Effect
We begin by reproducing the striking observation in [Fujimoto et al., 2019] that the passive learner generally fails to adequately learn from the very data stream that is demonstrably sufficient for its architecturally identical active counterpart; we refer to this phenomenon as the ‘tandem effect’.

Analysis of the Tandem Effect
The following three potential contributing factors in the tandem effect provide a natural structure to our analysis:
Bootstrapping (B) The passive agent’s bootstrapping from poorly estimated (in particular, overestimated) values causes any initially small mis-estimation to get amplified.
Data Distribution (D) Insufficient coverage of sub-optimal actions under the active agent’s policy may lead to their mis-estimation by the passive agent. In the case of over-estimation, this may lead to the passive agent’s under-performance.
Function Approximation (F) A non-linear function approximator used as a Q-value function may tend to wrongly extrapolate the values of state-action pairs underrepresented in the active agent’s behavior distribution. This tendency can be inherent and persistent, in the sense of being independent of initialization and not being reduced with increased training on the same data distribution.
These proposed contributing factors are not at all mutually exclusive; they may interact in causing or exacerbating the tandem effect. Insufficient coverage of sub-optimal actions under the active agent’s behavior distribution (D) may lead to insufficient constraint on the respective values, which allows for effects of erroneous extrapolation by a function approximator (F). Where this results in over-estimation, the use of bootstrapping (B) carries the potential to ‘pollute’ even well-covered state-action pairs by propagating over-estimated values (especially via the $\max$ operator in the case of Q-learning). In the next sections we empirically study these three factors in isolation, to establish their actual roles and relative contributions to the overall difficulty of passive learning.
The Role of Bootstrapping
In the Double-DQN algorithm the bootstrapping updates take the form $$ Q(s, a) \leftarrow r + \gamma \bar{Q}(s’, \arg\max_{a’} Q(s’, a’)) $$
where $\bar{Q}$ is the target network Q-value function, i.e. a time-delayed copy of $Q$.
Four value functions are involved in the active and passive updates of Tandem DQN: $Q_{\color{red} A}, \bar Q_{\color{red} A}, Q_{\color{blue} P}$ and $\bar Q_{\color{blue} P}$, where the ${\color{red} A}/{\color{blue} P}$ subscripts refer to the Q-value functions of the active and passive agents, respectively. The use of its own target network by the passive agent makes bootstrapping a plausible strong contributor to the tandem effect. To test this, we replace the target values and/or policies in the update equation for the passive agent, with the values provided by the active agent’s value functions:
$$ Q_P(s,a) \leftarrow \begin{cases} r + \gamma \bar Q_{\color{blue} P} (s’, \arg\max_{a’} Q_{\color{blue} P} (s’,a’))\qquad \text{Vanilla Tandem DQN}\\ r + \gamma \bar Q_{\color{red} A} (s’, \arg\max_{a’} Q_{\color{blue} P} (s’,a’))\qquad \text{Same Target $Q$} \\ r + \gamma \bar Q_{\color{blue} P} (s’, \arg\max_{a’} Q_{\color{red} A} (s’,a’))\qquad \text{Same Target $\pi$} \\ r + \gamma \bar Q_{\color{red} A} (s’, \arg\max_{a’} Q_{\color{red} A} (s’,a’))\qquad \text{Same Target $\pi$&$Q$} \\ \end{cases} $$
The use of the active value functions as targets reduces the active-passive gap by only a small amount. Note that when both active target values and policy are used, both networks are receiving an identical sequence of targets for their update computations, a sequence that suffices for the active agent to learn a successful policy. Strikingly, despite this the tandem effect appears largely preserved: in all but the easiest games (e.g. Pong) the passive agent fails to learn effectively.

To more precisely understand the effect of bootstrapping with respect to a potential value overestimation by the passive agent, we also show the values of the passive networks in the above experiment compared to those of the respective active networks. As hypothesised, we observe that the vanilla tandem setting leads to significant value over-estimation, and that indeed bootstrapping plays a substantial role in amplifying the effect: passive networks trained using the active network’s bootstrap targets do not over-estimate compared to the active network at all.

These findings indicate that a simple notion of value over-estimation itself is not the fundamental cause of the tandem effect, and that (B) plays an amplifying, rather than causal role. Additional evidence for this is provided below, where the tandem effect occurs in a purely supervised setting
The Role of the Data Distribution
The critical role of the data distribution for offline learning is well established. Here we extend past analysis empirically, by investigating how properties of the data distribution (e.g. stochasticity, stationarity, the size and diversity of the dataset, and its proximity to the passive agent’s own behavior distribution) affect its suitability for passive learning. without bootstrapping.
The exploration parameter
A simple way to affect the data distribution’s state-action coverage (albeit in a blunt and uniform way) is by varying the exploration parameter ε of the active agent’s $\epsilon$-greedy behavior policy (for training, not for evaluation). Note that a higher $\epsilon$ parameter affects the active agent’s own training performance, as its ability to navigate environments requiring precise control is reduced. We therefore report the relative passive performance (i.e. as a fraction of the active agent’s performance, which itself also varies across parameters), with absolute performance plots included in the (hidden) detail section below. We observe that the relative passive performance is indeed substantially improved when the active behavior policy’s stochasticity (and as a consequence its coverage of non-argmax actions along trajectories) is increased, and conversely it reduces with a greedier behavior policy, providing evidence for the role of (D).

Expand to see absolute performance plots

Sticky actions
An alternative potential source of stochasticity is the environment itself, e.g. the use of ‘sticky actions’ in Atari [Machado et al., 2018]: with fixed probability, an agent action is ignored (and the previous action repeated instead). This type of environment-side stochasticity should not be expected to cause new actions to appear in the behavior data, and indeed it shows no substantial impact on the tandem effect.

Replay size
Our results contrast with the strong offline RL results in [Agarwal et al., 2020]. We hypothesize that the difference is due to the vastly different dataset size (full training of 200M transitions vs. replay buffer of 1M). Interpolating between the tandem and the offline RL setting from [Agarwal et al., 2020], we increase the replay buffer size, thereby giving the passive agent access to somewhat larger data diversity and state-action coverage (this does not affect the active agent’s training as the active agent is constrained to only sample from the most recent 1M replay samples, as in the baseline variant). A larger replay buffer somewhat mitigates the passive agent’s under-performance, though it appears to mostly slow down rather than prevent the passive agent from eventually under-performing its active counterpart substantially.

Expand to see experiments on classic control environments
As we suspect that a sufficient replay buffer size may depend on the effective state-space size of an environment, we also perform analogous experiments on the (much smaller) classic control domains; results remain qualitatively the same.

Note that for a fixed dataset size, sample diversity can take different forms. Many samples from a single policy may provide better coverage of states on, or near, policy-typical trajectories. Meanwhile, a larger collection of policies, with fewer samples per policy, provides better coverage of many trajectories at the expense of lesser coverage of small deviations from each. To disentangle the impact of these modalities, while also shedding light on the role of stationarity of the distribution, we next switch to the ‘Forked Tandem’ variation of the experimental paradigm.
Fixed policy
Upon forking, the frozen active policy is executed to produce training data for the passive agent, which begins its training initialized with the active network’s weights. Note that this constitutes a stronger variant of the tandem experiment. At the time of forking, the agents do not merely share analogous architectures and equal ‘data history’, but also identical network weights (whereas in the simple tandem setting, the agents were distinguished by independently initialized networks). Moreover, the data used for passive training can be thought of as a ‘best-case scenario’: generated by a single fixed policy, identical to the passive policy at the beginning of passive training. Strikingly, the tandem effect is not only preserved but even exacerbated in this setting: after forking, passive performance decays rapidly in all but the easiest games, despite starting from a near-optimally performing initialization. This re-frames the tandem effect as not merely the difficulty of passively learning to act, but even to passively maintain performance. Instability appears to be inherent in the very learning process itself, providing strong support to the hypothesis that an interplay between (D) and (F) is critical to the tandem effect.

Expand to see experiments with stochasticity
We additionally show that similarly to the regular tandem setting, stochasticity of the active policy after forking influences the passive agent’s ability to maintain performance.

Fixed replay
A variation on the above experiments is to freeze the replay buffer while continuing to train the passive policy from this fixed dataset. Instead of a stream of samples from a single policy, this fixed data distribution now contains a fixed number of samples from a training process of the length of the replay buffer, i.e. from a number of different policies. The collapse of passive performance here is less rapid, yet qualitatively similar.

Expand to see extra experiments
We devise an experiment attempting to combine both: instead of freezing the active policy after forking, we continue training it (and filling the replay buffer), however after each iteration of 1M steps, the active network is reset to its parameter values at forking time. Effectively this produces a data stream that can be viewed as producing samples of the training process of a single iteration, a variant that we refer to as the ‘Groundhog day’ experiment. This setting combines the multiplicity of data-generating policies with the property of an unbounded dataset being presented to the passive agent. Indeed we observe that the groundhog day setting improves passive performance over the fixed-policy setting, while not clearly changing the outcome in comparison to the fixed-replay setting.

These experiments provide strong evidence for the importance of (D): a larger replay buffer, containing samples from more diverse policies, can be expected to provide an improved coverage of (currently) non-greedy actions, reducing the tandem effect. While the forked tandem begins passive learning with the seemingly advantageous high-performing initialization, state-action coverage is critically limited in this case. In the frozen-policy case, a large number of samples from the very same $\epsilon$-greedy policy can be expected to provide very little coverage of non-greedy actions, while in the frozen-replay case, a smaller number of samples from multiple policies can be expected to only do somewhat better in this regard. In both cases the tandem effect is highly pronounced.
On-policy evaluation
The strength of the forked tandem experiments lies in the observation that, since active and passive networks have identical parameter values at the beginning of passive training, their divergence cannot be attributed to small initial differences getting amplified by training on an inadequate data distribution. With so many factors held fixed, the collapse of passive performance when trained on the very data distribution produced by its own initial policy begs the question whether off-policy Q-learning itself is to blame for this failure mode, e.g. via statistical over-estimation bias introduced by the max operator. Here we provide a negative answer, by performing on-policy evaluation with SARSA:

We also perform purely supervised regression on the Monte-Carlo returns. In the top row, we report active vs. passive control performance, and in the bottom row average absolute Monte-Carlo error. The Monte-Carlo error is minimized effectively by the passive training, while the control performance of the resulting $\epsilon$-greedy policy collapses completely.
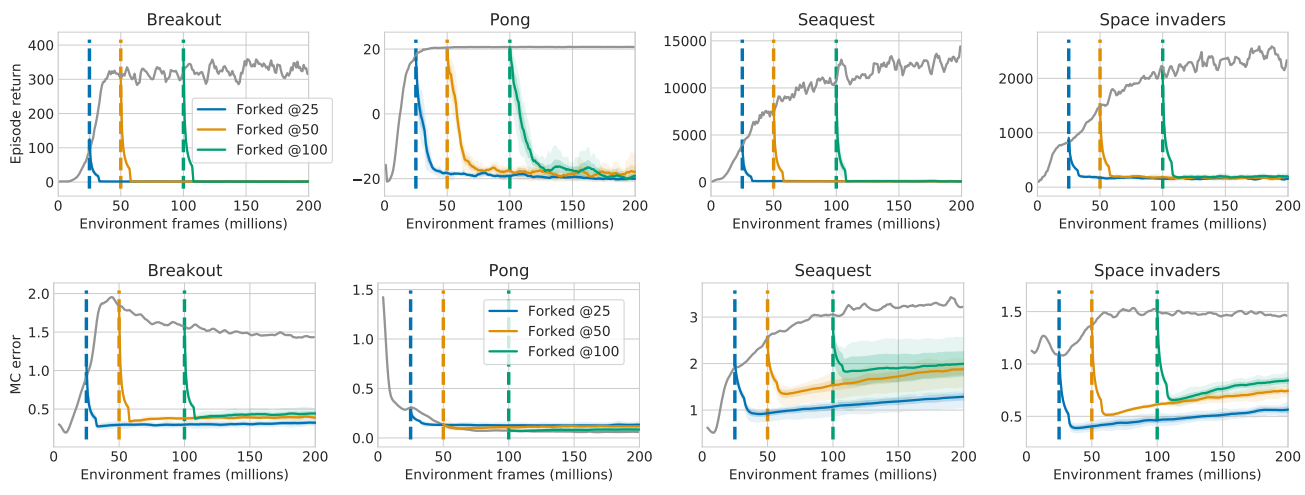
While evaluation succeeds, in the sense of minimizing evaluation error on the given behavior distribution, atypical action values under the behavior policy suffer substantial estimation error, resulting in occasional over-estimation. The resulting ε-greedy control policy under-performs the initial policy at forking time as catastrophically as in the other forked tandem experiments. Strengthening the roles of (D) and (F) while further weakening that of (B), these observations point to an inherent instability of offline learning, different from that of Baird’s famous example or the infamous ‘Deadly Triad’; an instability that results purely from erroneous extrapolation by the function approximator, when the utilized data distribution does not provide adequate coverage of relevant state-action pairs.
Self-generated data
Our final empirical question in this section is ‘How much data generated by the passive agent is needed to correct for the tandem effect?’. While a full investigation of this question exceeds the scope of this paper and is left for future work, the tandem setup lends itself to a simple experiment: both agents interact with the environment and fill individual replay buffers, one of them (for simplicity still referred to as ‘passive’) however learns from data stochastically mixed from both replay buffers. As shown below, even a moderate amount (10%-20%) of ‘own’ data yields a substantial reduction of the tandem effect, while a 50/50 mixture completely eliminates it.

The Role of Function Approximation
We structure our investigation of the role of function approximation in the tandem effect into two categories: the optimization process and the function class used.
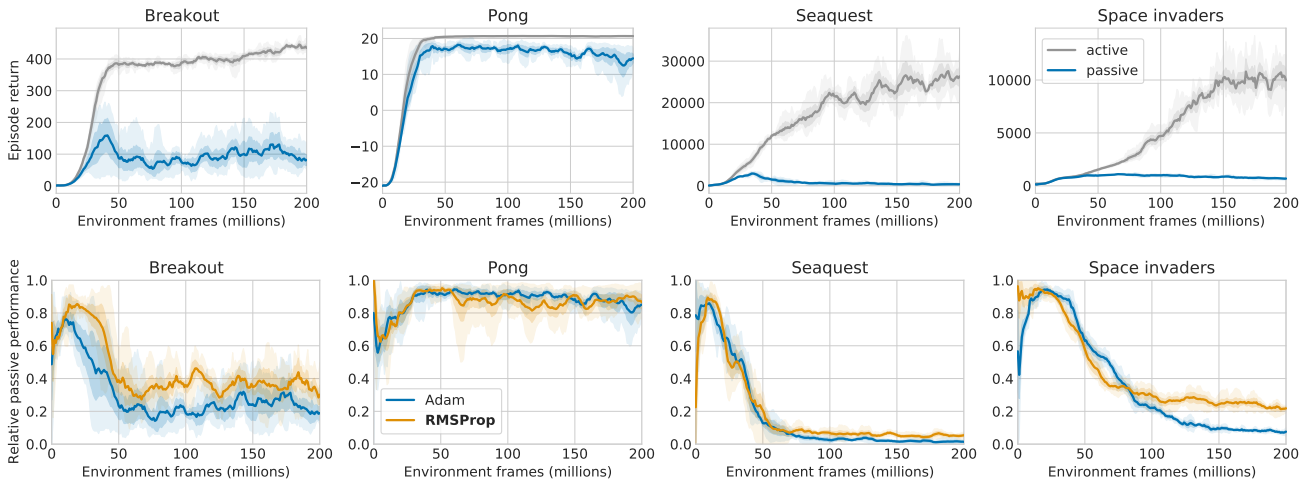
Optimization
We used RMSProp in our experiments, but recent papers (such as my recent Revisiting Rainbow paper) demonstrated that Adam yields better performance. We show that while both active and passive agents perform better with Adam, the tandem effect itself is unaffected by the choice of optimizer.
Another plausible hypothesis is that the passive network suffers from under-fitting and requires more updates on the same data to attain comparable performance to the active learner. Varying the number of passive agent updates per active agent update step, we find that more updates worsen the performance of the passive agent. This rejects insufficient training as a possible cause, and further supports the role of (D).

Function class
Given that the active and passive agents share an identical network architecture, the passive agent’s under-performance cannot be explained by an insufficiently expressive function approximator. Performing the tandem experiment with pure regression of the passive network’s outputs towards the active network’s (a variant of network distillation), instead of TD based training, we observe that the performance gap is indeed vastly reduced and in some games closed entirely; however, strikingly, it remains in some.

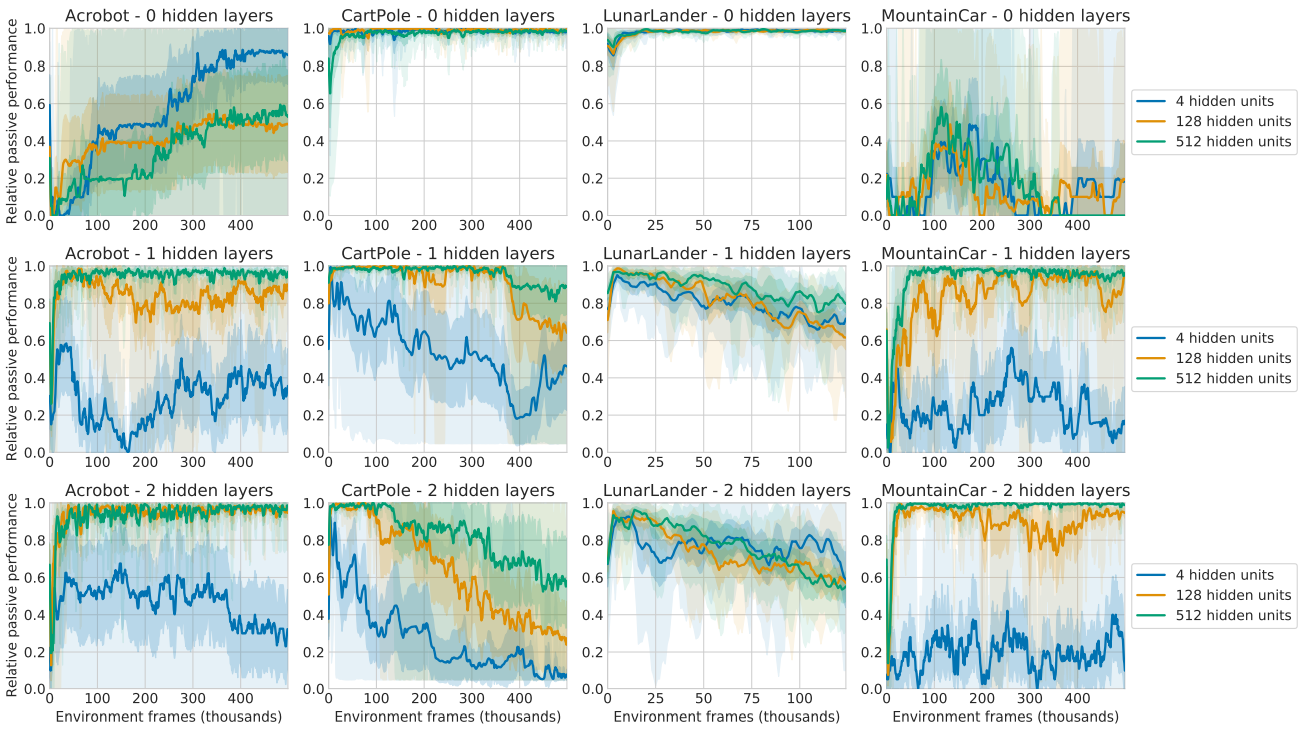
Next, we vary the function class of both networks by varying the depth and width of the utilized Q-networks on a set of Classic Control tasks. As we can see below, the magnitude of the active-passive performance gap appears negatively correlated with network width, which is in line with (F): an increase in network capacity results in less pressure towards over-generalizing to infrequently seen action values and an ultimately smaller tandem effect. On the other hand, the gap seems to correlate positively with network depth. We speculate that this may relate to the finding that deeper networks tend to be biased towards simpler (e.g. lower rank) solutions, which may suffer from increased over-generalization.
Finally, we investigate varying the function class of only the passive network by sharing the weights of the first $k$ (out of $5$) layers of active and passive networks, while constraining the passive network to only update the remaining top $5 − k$ layers, and using the ‘representation’ at layer $k$ acquired through active learning only. This reduces the ‘degrees of freedom’ of the passive agent, which we hypothesize reduces its potential for divergence. Indeed, as we see below, passive performance correlates strongly with the number of tied layers, with the variant for which only the linear output layer is trained passively performing on par with the active agent.

A similar result is obtained in the forked tandem setting:
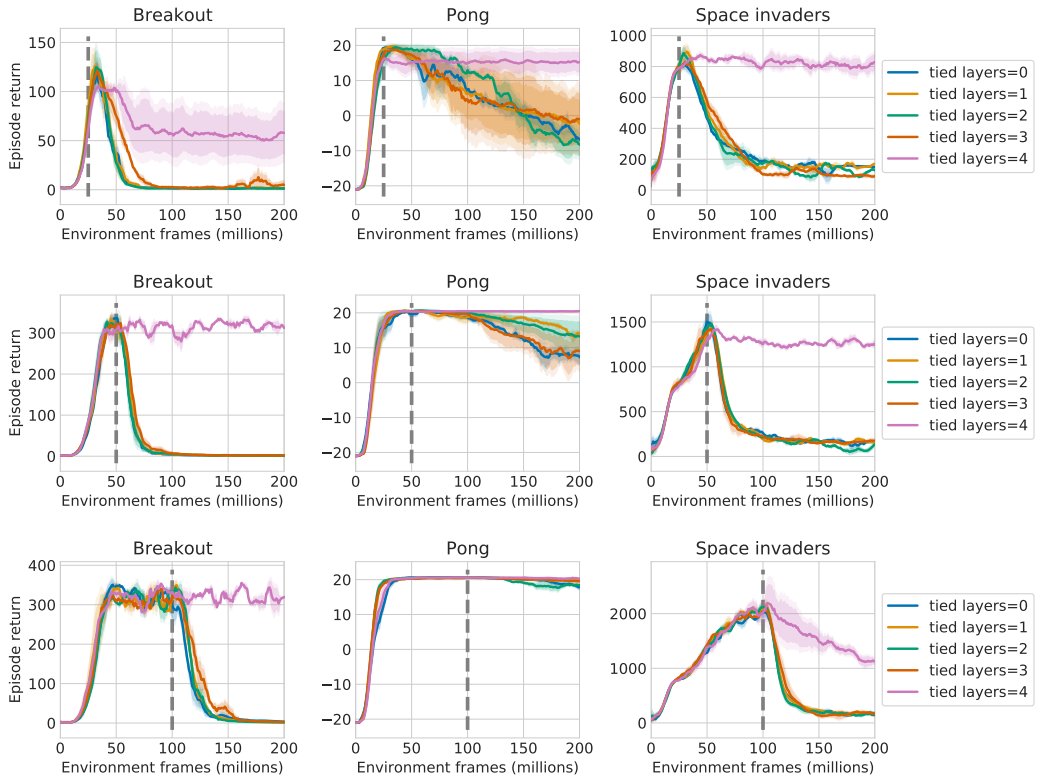
This finding provides a strong indirect hint towards (F): with only part of the network’s layers being trained passively, much of its ‘generalization capacity’ is shared between active and passive agents. States that are not aggregated by the shared bottom layers (only affected by active training) have to be ‘erroneously’ aggregated by the remaining top layers of the network for over-generalization to occur.
Applications of the Tandem Setting
In addition to being valuable for studying the challenges in offline RL, we propose that the Tandem RL setting provides analytic capabilities that make it a useful tool in the empirical analysis of general (online) reinforcement learning algorithms. At its core, the tandem setting aims to decouple learning dynamics from its impact on behavior and the data distribution, which are inseparably intertwined in the online setting. While classic offline RL achieves a similar effect, as an analytic tool it has the potential downside of typically using a stationary distribution. Tandem RL, on the other hand, presents the passive agent with a data distribution which realistically represents the type of non-stationarity encountered in an online learning process, while still holding that distribution independent from the learning dynamics being studied. This allows Tandem RL to be used to study, e.g., the impact of variations in the learning algorithm on the quality of a learned representation, without having to control for the indirect confounding effect of a different behavior causing a different data distribution.
While extensive examples of this exceed the scope of this paper, we provide a single such experiment, testing QR-DQN as a passive learning algorithm (the active agent being a Double-DQN). This is motivated by the observation of Agarwal et al. [2020], that QR-DQN outperforms DQN in the offline setting. QR-DQN indeed appears to be a nontrivially different passive learning algorithm, significantly better in some games, while curiously worse in others.

Discussion and Conclusion
At a high level, our work can be viewed as investigating the issue of (in)compatibility between the data distribution used to train a function approximator and the data distribution relevant in its evaluation. While in supervised learning, generalization can be viewed as the problem of transfer from a training to a (given) test distribution, the fundamental challenge for control in reinforcement learning is that the test distribution is created by the very outcome of learning itself, the learned policy. The various difficulties of learning to act from offline data alone throw into focus the role of interactivity in the learning process: only by continuously interacting with the environment does an agent gradually ‘unroll’ the very data on which its performance will be evaluated.
This need not be an obstacle in the case of exact (i.e. tabular) functions: with sufficient data, extrapolation error can be avoided entirely. In the case of function approximation however, as small errors compound rapidly into a difference in the underlying state distribution, significant divergence and, as this and past work demonstrates, ultimately catastrophic under-performance can occur. Function approximation plays a two-fold role here: (1) being an approximation, it allows deviations in the outputs; (2) as the learned quantity, it is (especially in the non-linear case) highly sensitive to variations in the input distribution. When evaluated for control after offline training, these two roles combine in a way that is ‘unexplored’ by the training process: minor output errors cause a drift in behavior, and thereby a drift in the test distribution.
While related, this challenge is subtly different from the well-known divergence issues of off-policy learning with function approximation, demonstrated by Baird’s famous counterexample and conceptualized as the Deadly Triad. While these depend on bootstrapping as a mechanism to cause a feedback-loop resulting in value divergence, our results show that the offline learning challenge persists even without bootstrapping, as small differences in behavior cause a drift in the ‘test distribution’ itself. Instead of a training-time output drift caused by bootstrapping, the central role is taken by a test-time drift of the state distribution caused by the interplay of function approximation and a fixed data distribution (as opposed to dynamically self-generated data).
Our empirical work highlights the importance of interactivity and ‘learning from your own mistakes’ in learning control. Starting out as an investigation of the challenges in offline reinforcement learning, it also provides a particular viewpoint on the classical online reinforcement learning case. Heuristic explanations for highly successful deep RL algorithms like DQN, based on intuitions from (e.g.) approximate policy iteration, need to be viewed with caution in light of the apparent hardness of a policy improvement step based on approximate policy evaluation with a function approximator.
Finally, the forked tandem experiments show that even high-performing initializations are not robust to a collapse of control performance, when trained under their own (but fixed!) behavior distribution. Not just learning to act, but even maintaining performance appears hard in this setting. This provides an intuition that we distill into the following working conjecture:
Conjecture: The dynamics of deep reinforcement learning for control are unstable on (almost) any fixed data distribution.
Expanding on the classical on- vs. off-policy dichotomy, we propose that indefinitely training on any fixed data distribution, without strong explicit regularization or additional inductive bias, gives rise to ‘exploitation of gaps in the data’ by a function approximator, akin to the over-fitting occurring when over-training on a fixed dataset in supervised learning. Interaction, i.e. generating at least moderate amounts of one’s own experience, appears to be a powerful, and for the most part necessary, regularizer and stabilizer for learning to act, by creating a dynamic equilibrium between optimization of a function approximator and its own data-generation process.
Acknowledgements
We would like to thank Hado van Hasselt and Joshua Greaves for feedback on an early draft of this paper, and Zhongwen Xu for an unpublished related piece of work at DeepMind that inspired some of our experiments. We also thank Clare Lyle, David Abel, Diana Borsa, Doina Precup, John Quan, Marc G. Bellemare, Mark Rowland, Michal Valko, Remi Munos, Rishabh Agarwal, Tom Schaul and Yaroslav Ganin, and many other colleagues at DeepMind and Google Brain for the numerous discussions that helped shape this research.
comments powered by Disqus