
Pablo Samuel Castro
June 19, 2023
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
We identify the dormant neuron phenomenon in deep reinforcement learning, where an agent’s network suffers from an increasing number of inactive neurons, thereby affecting network expressivity.
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro*, Utku Evci*
This blogpost is a summary of our ICML 2023 paper. The code is available here. Many more results and analyses are available in the paper, so I encouraged you to check it out if interested!
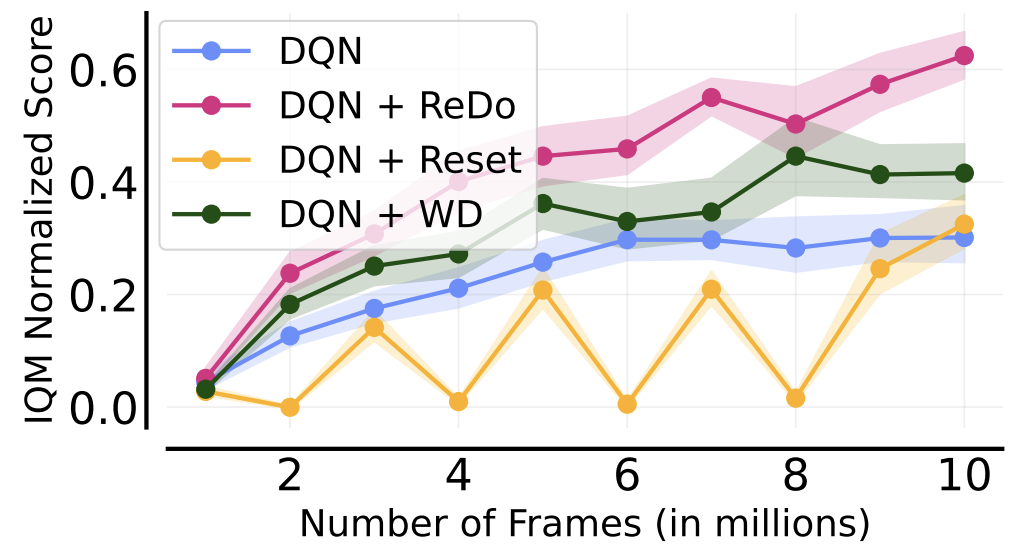
The following figure gives a nice summary of the overall findings of our work (we are reporting the Interquantile Mean (IQM) as introduced in our Statistical Precipice NeurIPS'21 paper):
- Dormant neurons reduce the expressivity and plasticity of deep networks during RL training.
- Our method (ReDo) reduces the number of dormant neurons and improves performance.
- The idea is comparable to network resets, but does not suffer performance degradation after each reset.
Introduction
In this work, we seek to understand the underlying reasons behind the loss of expressivity during the training of RL agents. The observed decrease in the learning ability over time raises the following question: Do RL agents use neural network parameters to their full potential? To answer this, we analyze neuron activity throughout training and track dormant neurons: neurons that have become practically inactive through low activations. Our analyses reveal that the number of dormant neurons increases as training progresses, an effect we coin the “dormant neuron phenomenon”. Specifically, we find that while agents start the training with a small number of dormant neurons, this number increases as training progresses. The effect is exacerbated by the number of gradient updates taken per data collection step. This is in contrast with supervised learning, where the number of dormant neurons remains low throughout training.
We demonstrate the presence of the dormant neuron phenomenon across different algorithms and domains. To address this issue, we propose Recycling Dormant neurons (ReDo), a simple and effective method to avoid network under-utilization during training without sacrificing previously learned knowledge: we explicitly limit the spread of dormant neurons by “recycling” them to an active state. ReDo consistently maintains the capacity of the network throughout training and improves the agent’s performance (see figure above).
Background
See this post for a background on reinforcement learning. Some extra background not covered in that post follows.
The number of gradient updates performed per environment step is known as the replay ratio. This is a key design choice that has a substantial impact on performance. Increasing the replay ratio can increase the sample-efficiency of RL agents as more parameter updates per sampled trajectory are performed. However, prior works have shown that training agents with a high replay ratio can cause training instabilities, ultimately resulting in decreased agent performance (Nikishin et al., 2022).
One important aspect of reinforcement learning, when contrasted with supervised learning, is that RL agents train on highly non-stationary data, where the non-stationarity is coming in a few forms, but we focus on two of the most salient ones.
Input data non-stationarity: The data the agent trains on is collected in an online manner by interacting with the environment using its current policy $\pi$; this data is then used to update the policy, which affects the distribution of future samples.
Target non-stationarity: The learning target used by RL agents is based on its own estimate $Q_{\tilde{\theta}}$, which is changing as learning progresses.
The Dormant Neuron Phenomenon
Definition
Given an input distribution $D$, let $h^\ell_i(x)$ denote the activation of neuron $i$ in layer $\ell$ under input $x\in D$ and $H^\ell$ be the number of neurons in layer $\ell$. We define the score of a neuron $i$ (in layer $\ell$) via the normalized average of its activation as follows: $$ s^{\ell}_i = \frac{\mathbb{E}_{x\in D} |h^{\ell}_i(x)|}{\frac{1}{H^{\ell}}\sum_{k\in h}\mathbb{E}_{x\in D}|h^{\ell}_k(x)|} $$ We say a neuron $i$ in layer $\ell$ is $\tau$-dormant if $s^{\ell}_i \leq \tau$.
We normalize the scores such that they sum to 1 within a layer. This makes the comparison of neurons in different layers possible.
Definition
An algorithm exhibits the dormant neuron phenomenon if the number of $|tau$-dormant neurons in its neural network increases steadily throughout training.
Present in deep RL agents
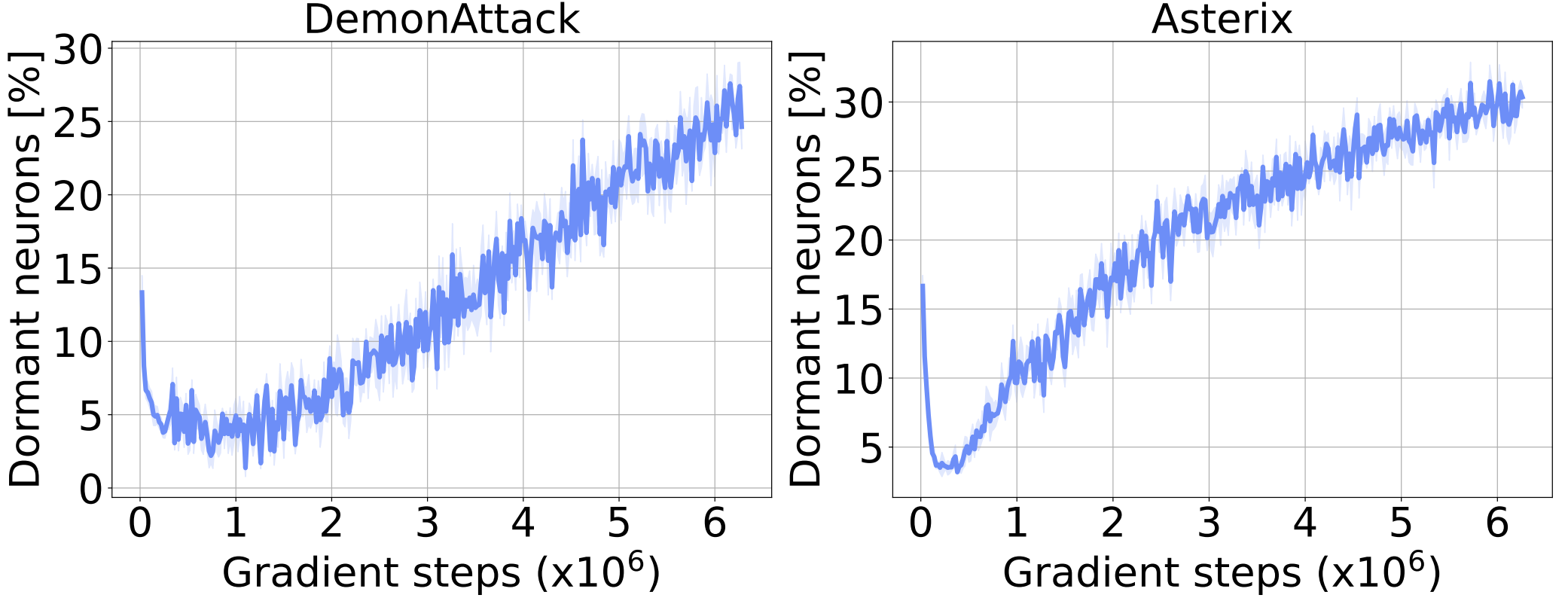
We begin our analyses by tracking the number of dormant neurons during DQN training. In the figure below, we observe that the percentage of dormant neurons steadily increases throughout training. This observation is consistent across different algorithms and environments.
Exacerbated by target non-stationarity
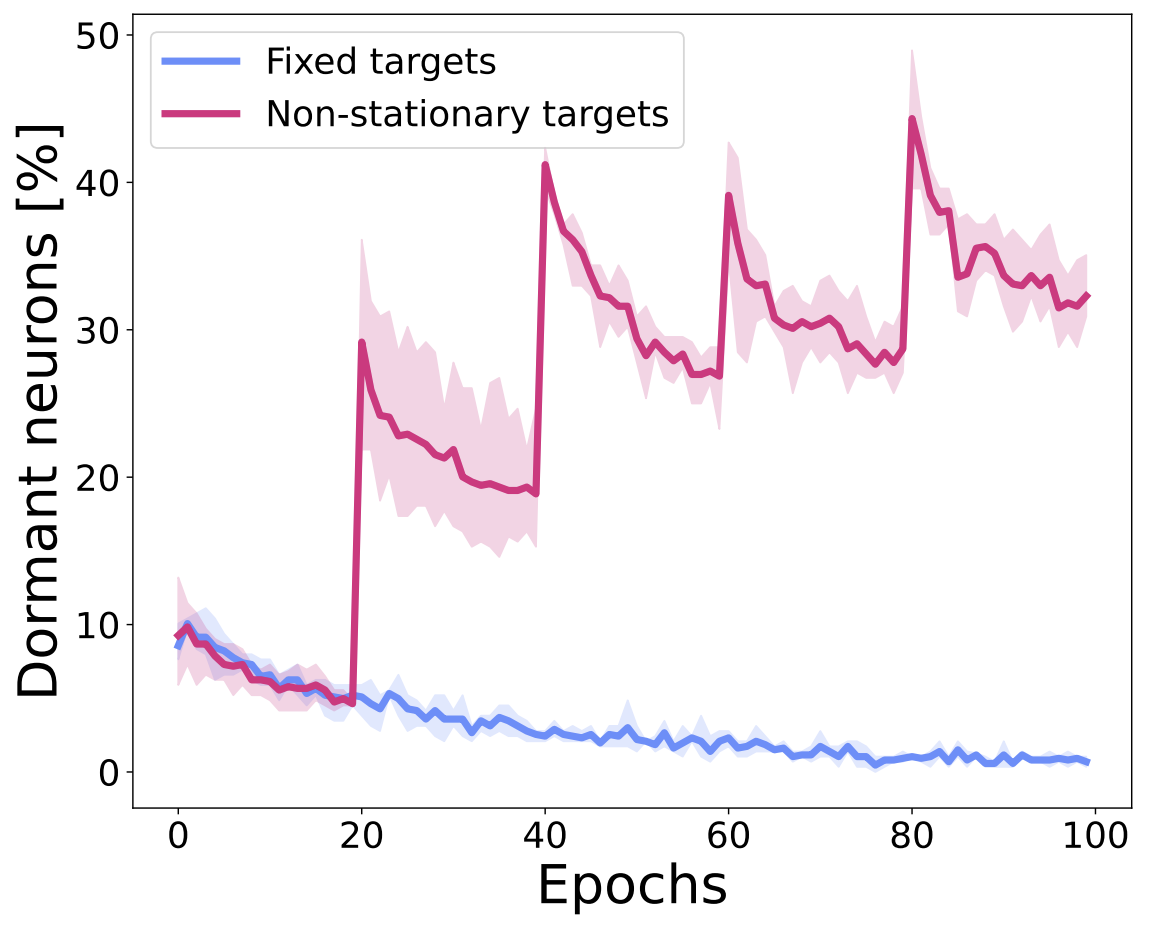
We hypothesize that the non-stationarity of training deep RL agents is one of the causes for the dormant neuron phenomenon. To evaluate this hypothesis, we consider two supervised learning scenarios using the standard CIFAR-10 dataset: (1) training a network with fixed targets, and (2) training a network with non-stationary targets, where the labels are shuffled throughout training. As the figure below shows, the number of dormant neurons decreases over time with fixed targets, but increases over time with non-stationary targets. Indeed, the sharp increases in the figure correspond to the points in training when the labels are shuffled. These findings suggest that the continuously changing targets in deep RL are a significant factor for the presence of the phenomenon.
Input non-stationarity not a major factor
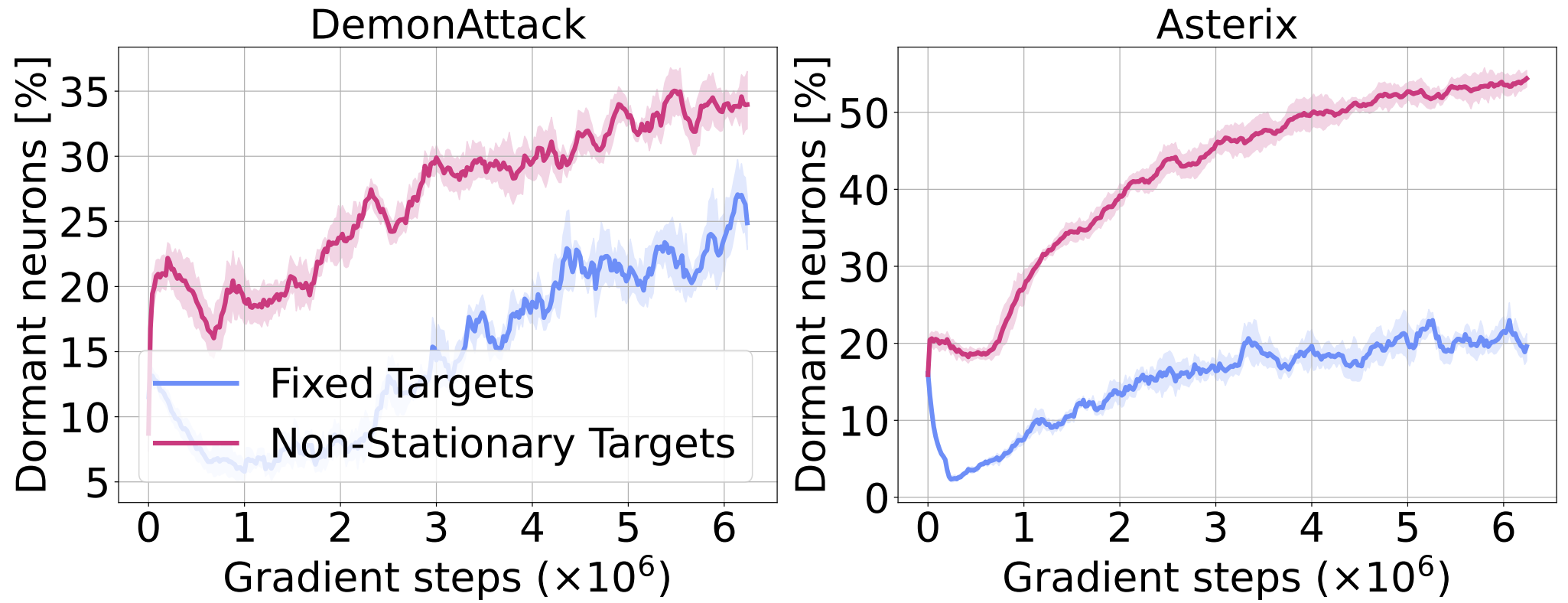
To investigate whether the non-stationarity due to online data collection plays a role in exacerbating the phenomenon, we measure the number of dormant neurons in the offline RL setting, where an agent is trained on a fixed dataset. In the figure below we can see that the phenomenon remains in this setting, suggesting that input non-stationary is not one of the primary contributing factors. To further analyze the source of dormant neurons in this setting, we train RL agents with fixed random targets (ablating the nonstationarity in inputs and targets). The decrease in the number of dormant neurons observed in this case supports our hypothesis that target non-stationarity in RL training is the primary source of the dormant neuron phenomenon.
Dormant neurons remain dormant
To investigate whether dormant neurons “reactivate” as training progresses, we track the overlap in the set of dormant neurons. The figure below plots the overlap coefficient between the set of dormant neurons in the penultimate layer at the current iteration, and the historical set of dormant neurons. The increase shown in the figure strongly suggests that once a neuron becomes dormant, it remains that way for the rest of training.
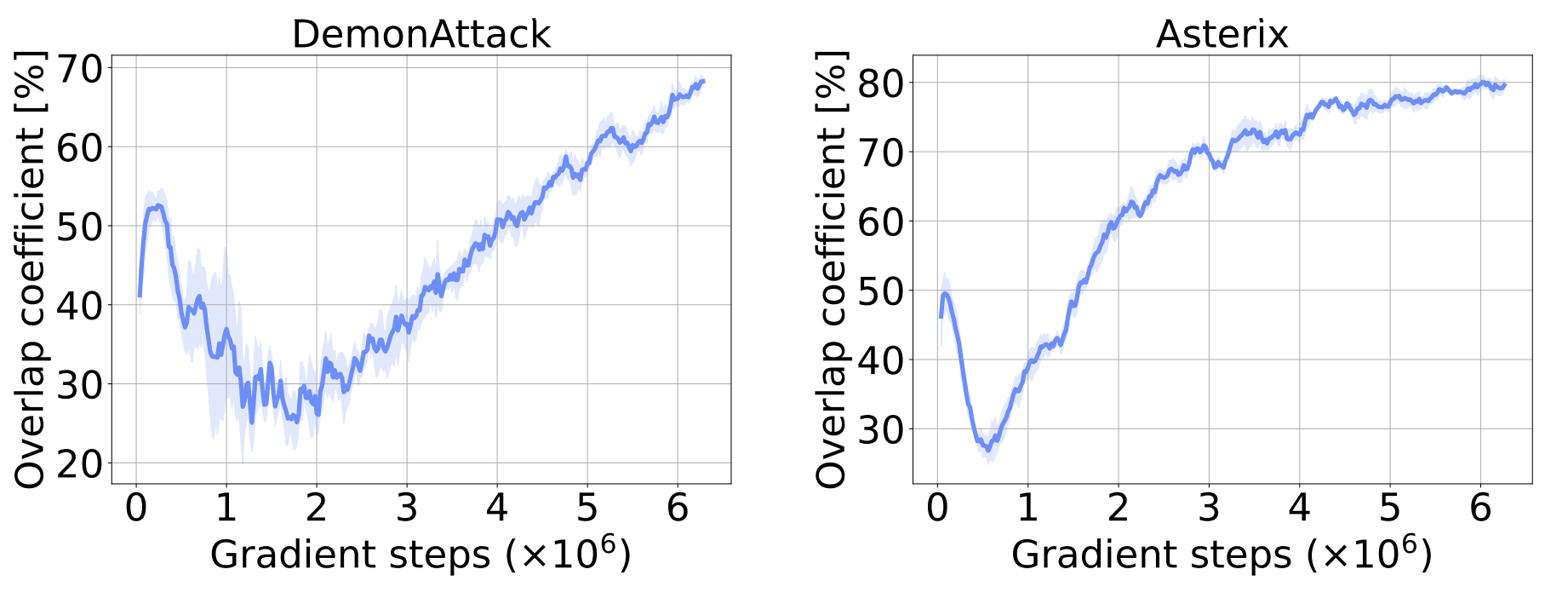
To further investigate this, we explicitly prune any neuron found dormant throughout training, to check whether their removal affects the agent’s overall performance. As the figure below shows, their removal does not affect the agent’s performance, further confirming that dormant neurons remain dormant.
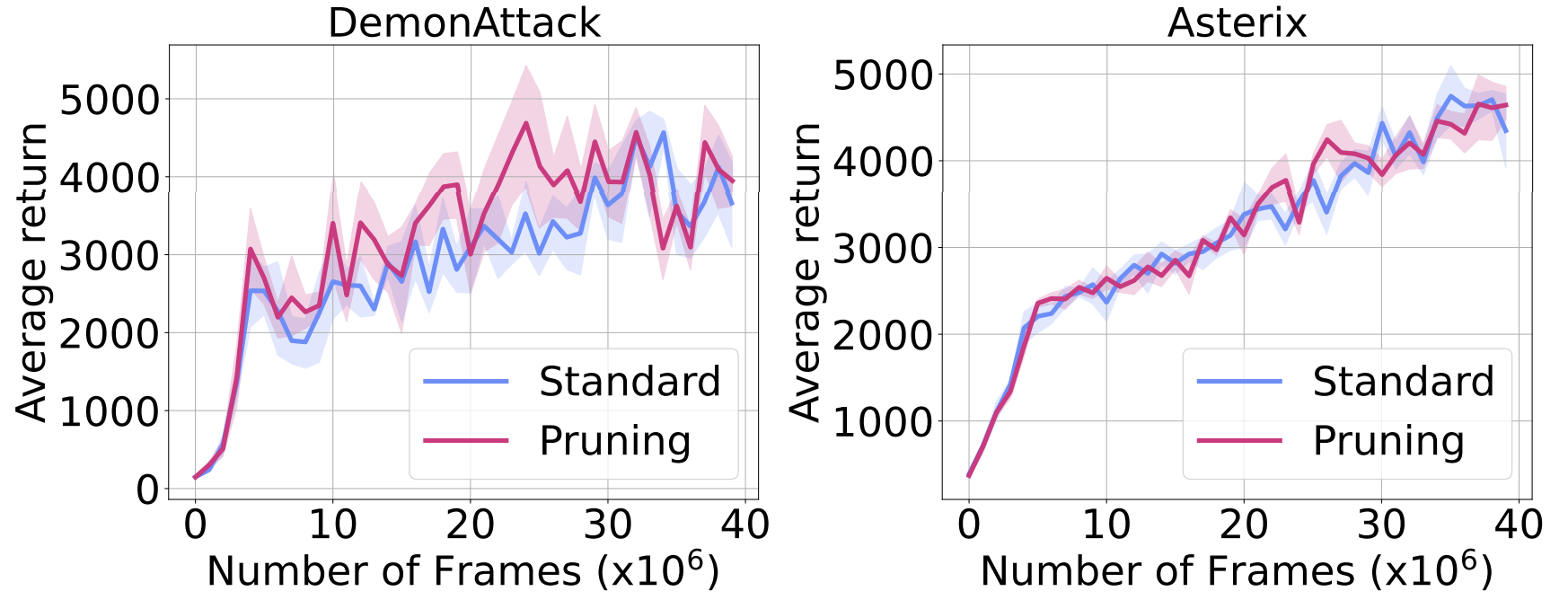
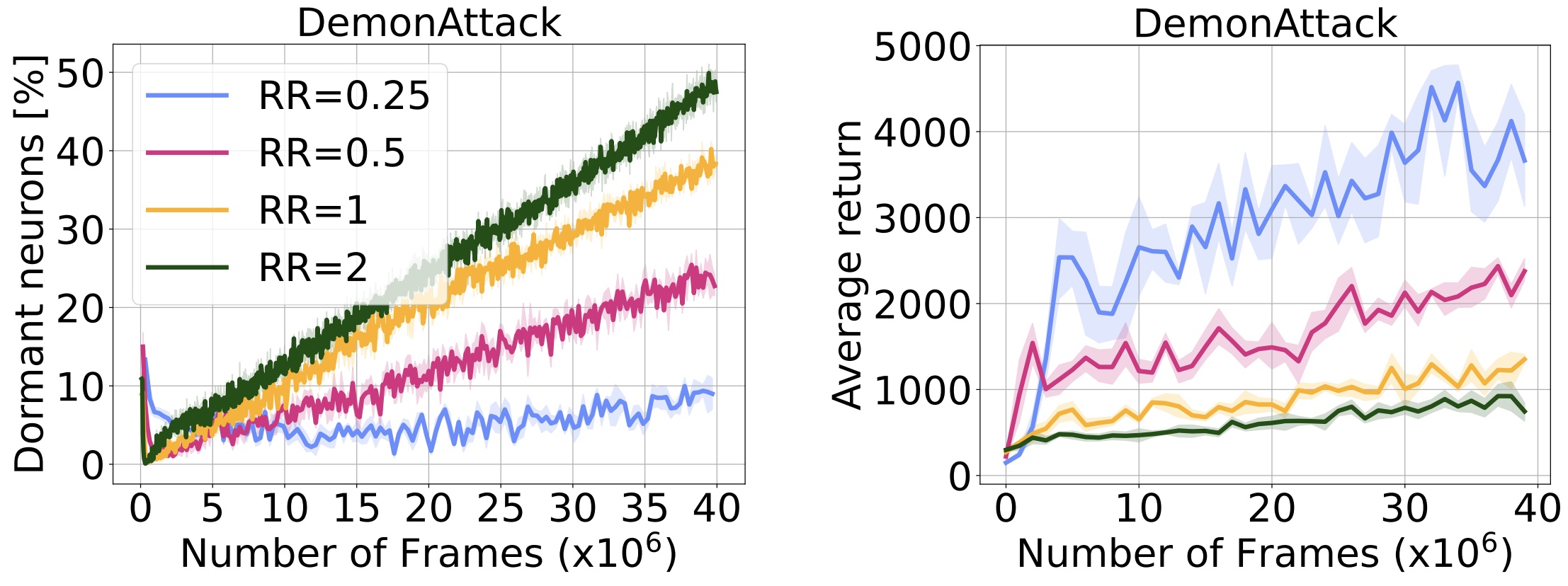
Made worse by more gradient updates
Although an increase in replay ratio can seem appealing from a data-efficiency point of view (as more gradient updates per environment step are taken), it has been shown to cause overfitting and performance collapse. In the figure below we measure neuron dormancy while varying the replay ratio, and observe a strong correlation between replay ratio and the fraction of neurons turning dormant. Although difficult to assert conclusively, this finding could account for the difficulty in training RL agents with higher replay ratios.
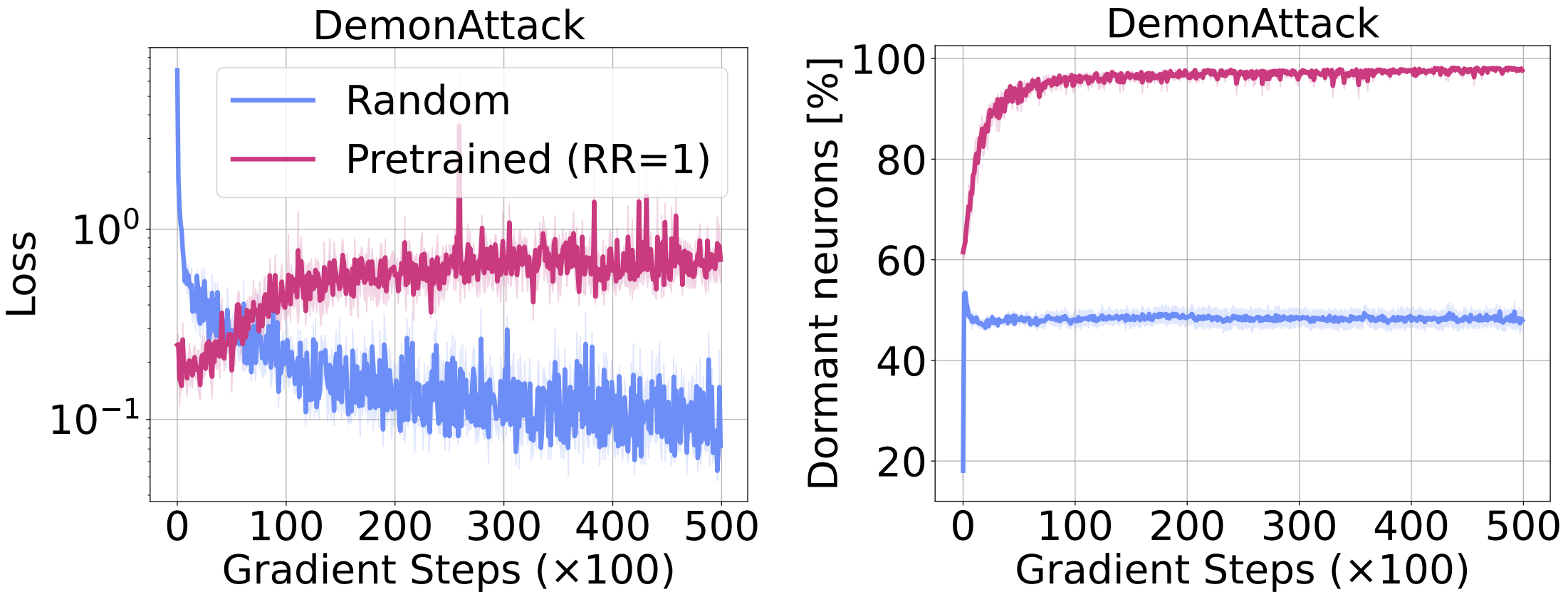
New tasks are more difficult
We directly examine the effect of dormant neurons on an RL network’s ability to learn new tasks. To do so, we train a DQN agent with a replay ratio of 1 (this agent exhibits a high level of dormant neurons as observed in the figure above). Next we fine-tune this network by distilling it towards a well performing DQN agent’s network, using a traditional regression loss and compare this with a randomly initialized agent trained using the same loss. In the figure below we see that the pre-trained network, which starts with a high level of dormant neurons, shows degrading performance throughout training; in contrast, the randomly initialized baseline is able to continuously improve. Further, while the baseline network maintains a stable level of dormant neurons, the number of dormant neurons in the pre-trained network continues to increase throughout training.
Recycling Dormant Neurons (ReDo)
We propose to recycle dormant neurons periodically during training (ReDo). The main idea of ReDo, outlined in the algorithm below, is rather simple: during regular training, periodically check in all layers whether any neurons are $\tau$-dormant; for these, reinitialize their incoming weights and zero out the outgoing weights. The incoming weights are initialized using the original weight distribution. Note that if $\tau$ is 0, we are effectively leaving the network’s output unchanged; if $\tau$ is small, the output of the network is only slightly changed.

The figure below showcases the effectiveness of ReDo in dramatically reducing the number of dormant neurons, which also results in improved agent performance.
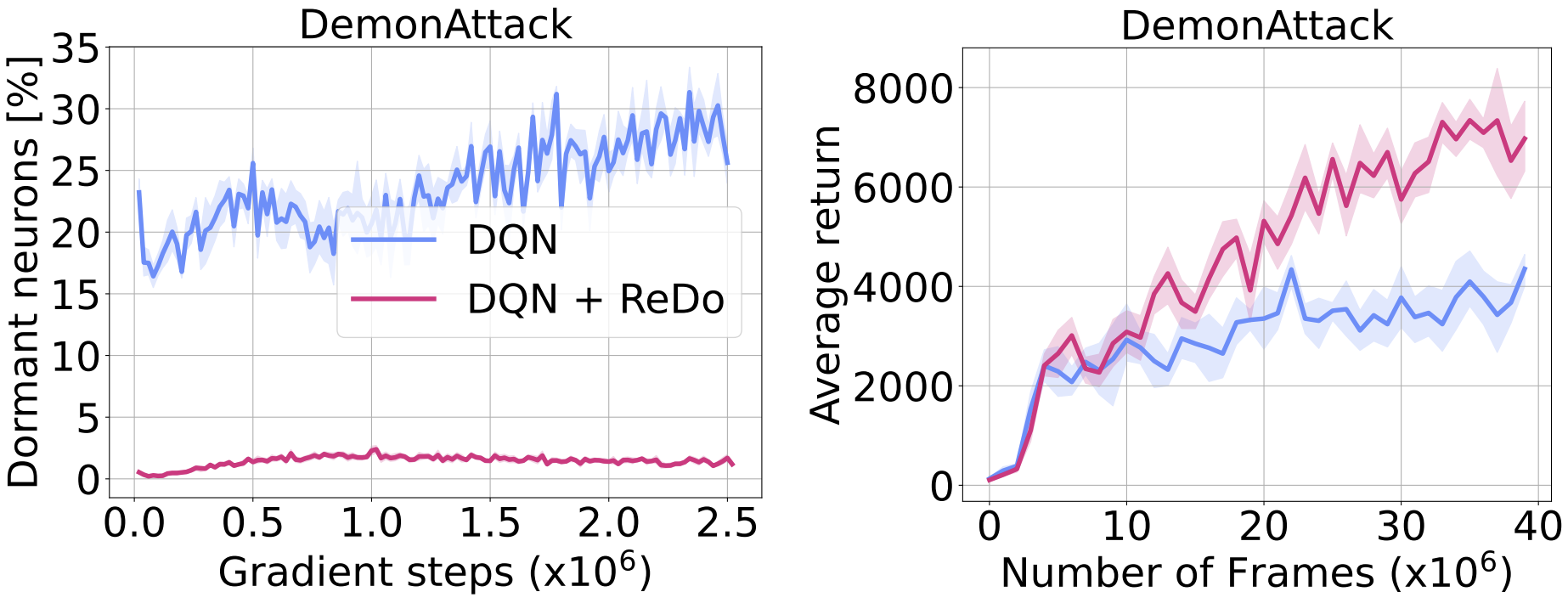
Empirical evaluations
We evaluate DQN on 17 games from the Arcade Learning Environment. We study two different architectures: the default CNN used by the original DQN paper, and the ResNet architecture used by the IMPALA agent. Additionally, we evaluate DrQ($\epsilon$) on the 26 games used in the Atari 100K benchmark, and SAC on four MuJoCo environments.
All our experiments and implementations were conducted using the Dopamine framework. For agents trained with ReDo, we use a threshold of $\tau = 0.1$, unless otherwise noted, as we found this gave a better performance than using a threshold of 0 or 0.025. When aggregating results across multiple games, we report the Interquantile Mean (IQM) using 5 independent seeds for each DQN experiment, 10 for the DrQ and SAC experiments, and reporting 95% stratified bootstrap confidence intervals.
Sample efficiency
Motivated by our finding that higher replay ratios exacerbate dormant neurons and lead to poor performance, we investigate whether ReDo can help mitigate these. To do so, we report the IQM for four replay ratio values: 0.25 (default for DQN), 0.5, 1, and 2 when training with and without ReDo. Since increasing the replay ratio increases the training time and cost, we train DQN for 10M frames, as opposed to the regular 200M. As the figure below demonstrates, ReDo is able to avoid the performance collapse when increasing replay ratios, and even to benefit from the higher replay ratios when trained with ReDo.
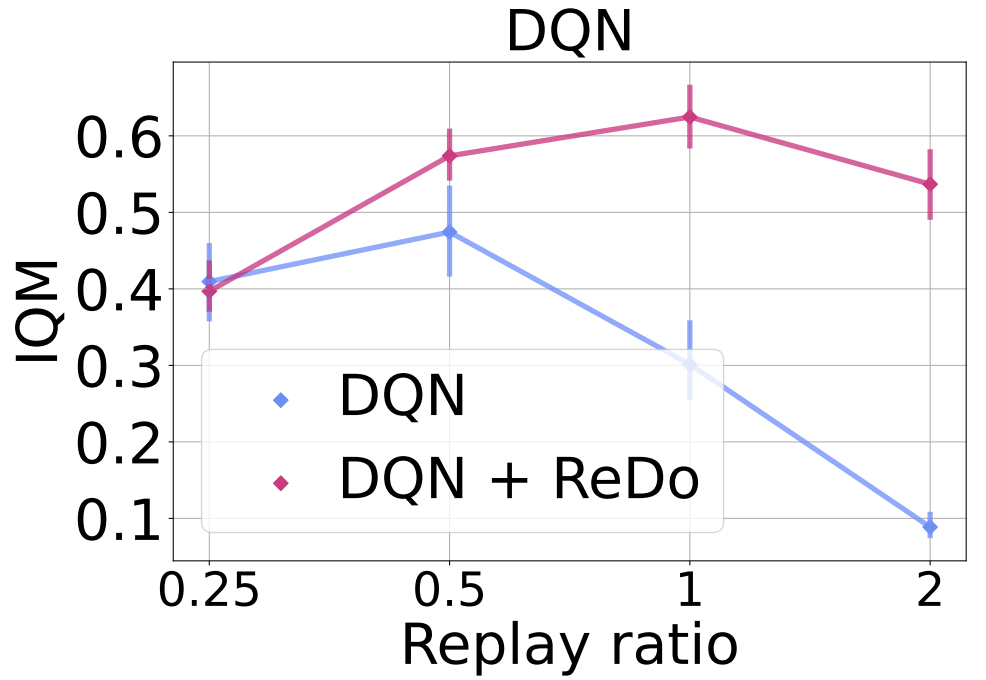
In the figure below we added $n$-step returns with a value of $n = 3$. While this change results in a general improvement in DQN’s performance, it still suffers from performance collapse with higher replay ratios; ReDo mitigates this and improves performance across all values.
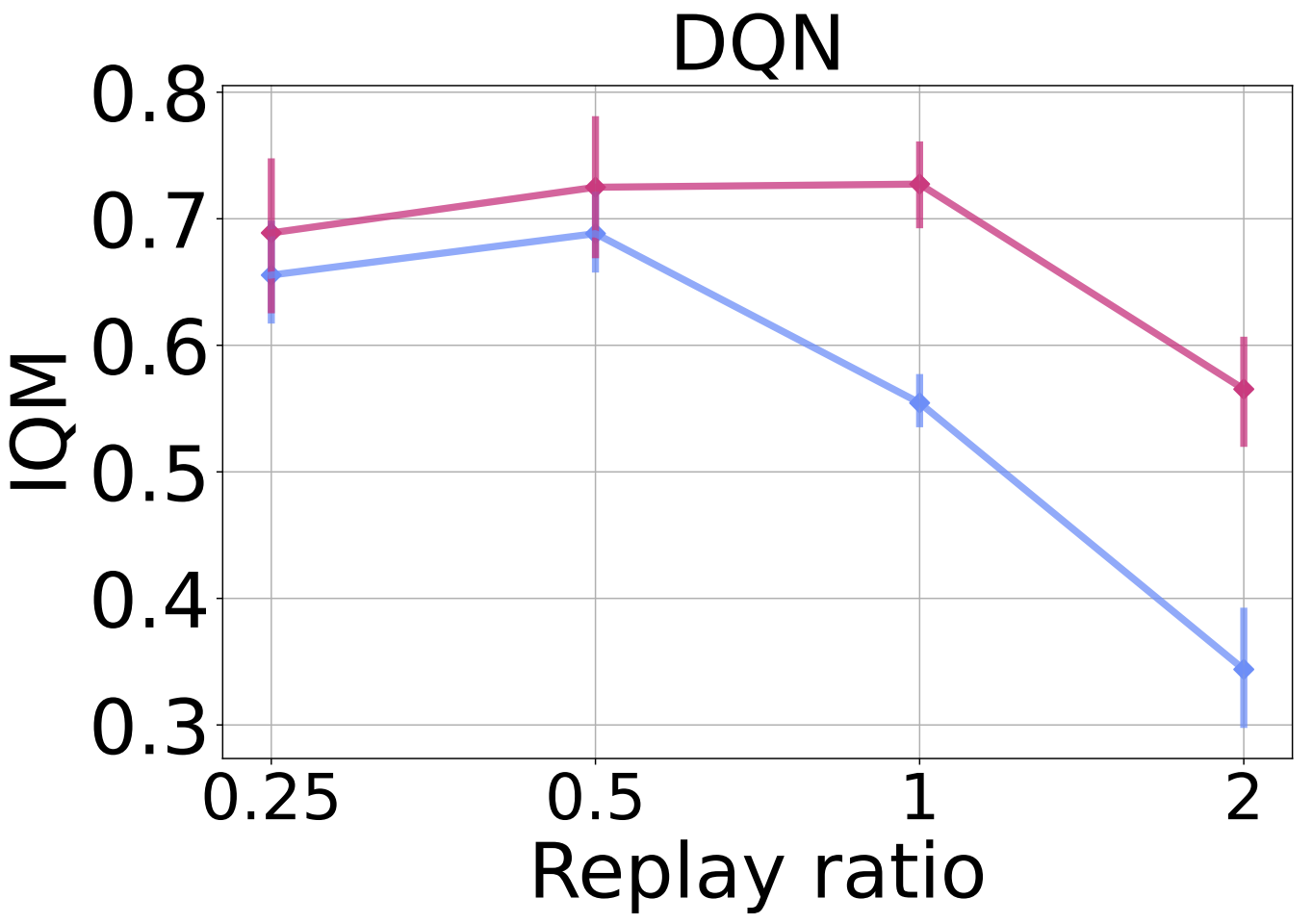
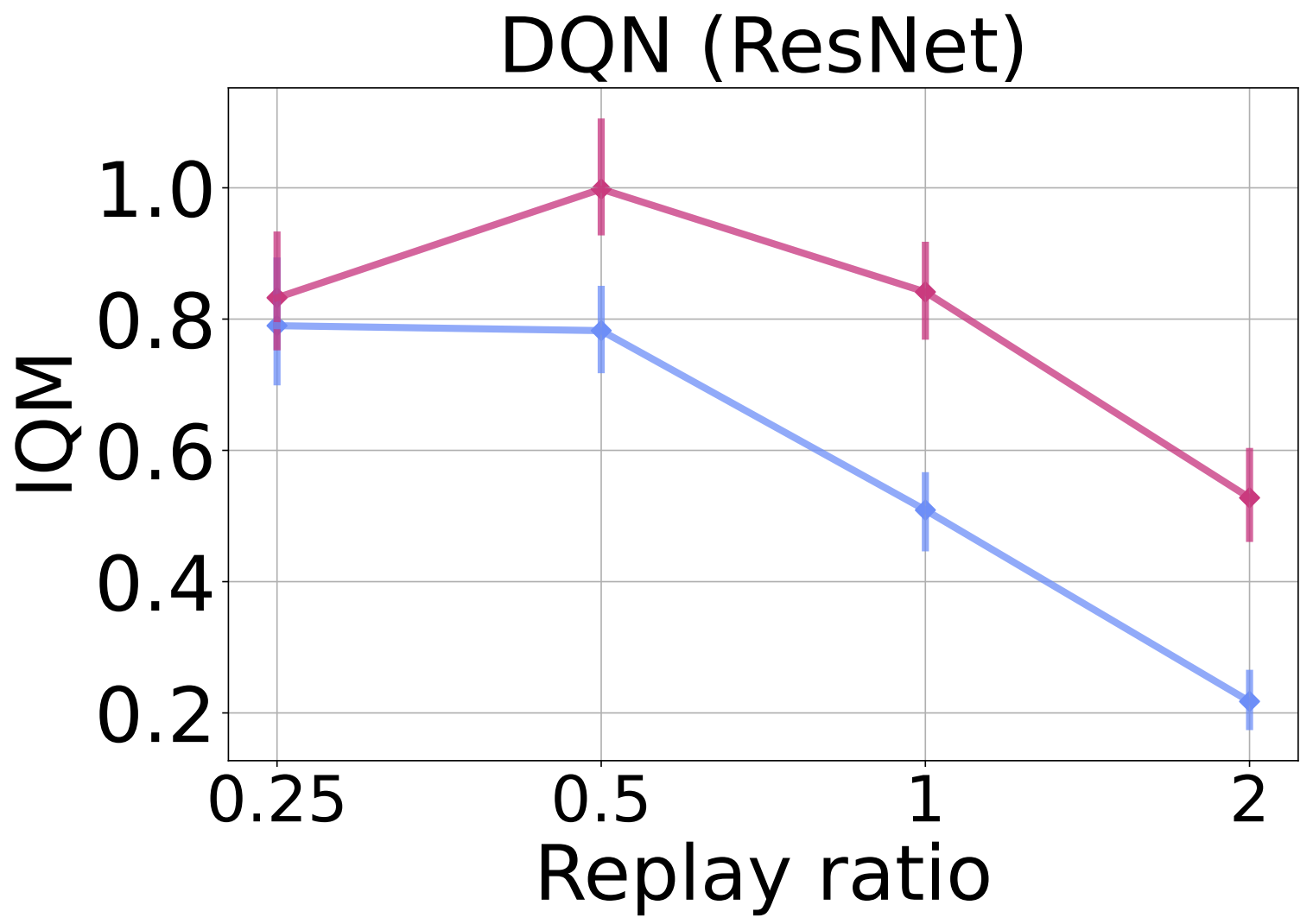
To evaluate ReDo’s impact on different network architectures, in the figure below we replace the default CNN architecture used by DQN with the ResNet architecture used by the IMPALA agent. We see a similar trend: ReDo enables the agent to make better use of higher replay ratios, resulting in improved performance.
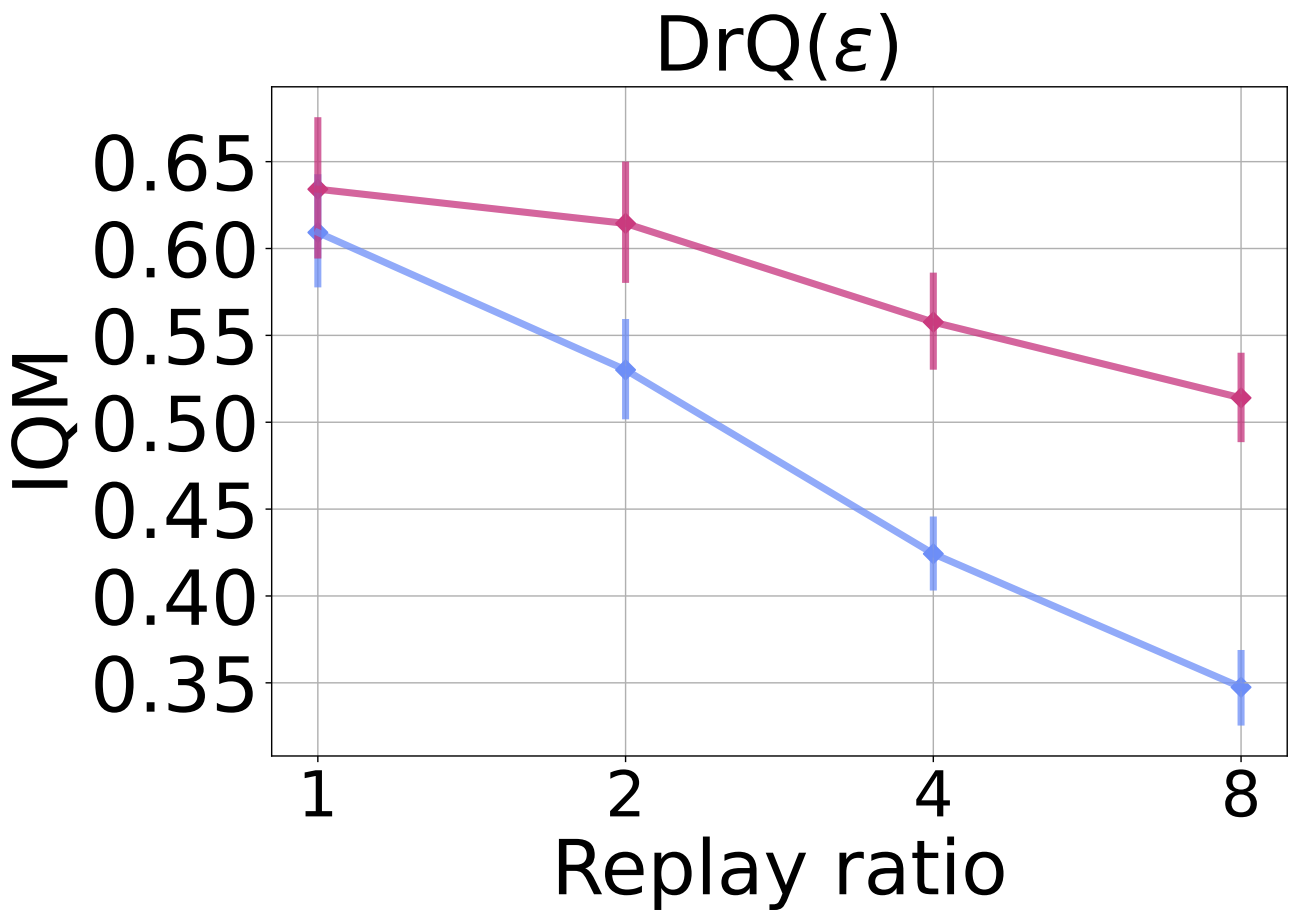
We evaluate on a sample-efficient valuebased agent DrQ($\epsilon$) on the Atari 100K benchmark in the figure below. In this setting, we train for 400K steps, where we can see the effect of dormant neurons on performance, and study the following replay ratio values: 1 (default), 2, 4, 8. Once again, we observe ReDo’s effectiveness in improving performance at higher replay ratios.
Over-parameterization is not enough
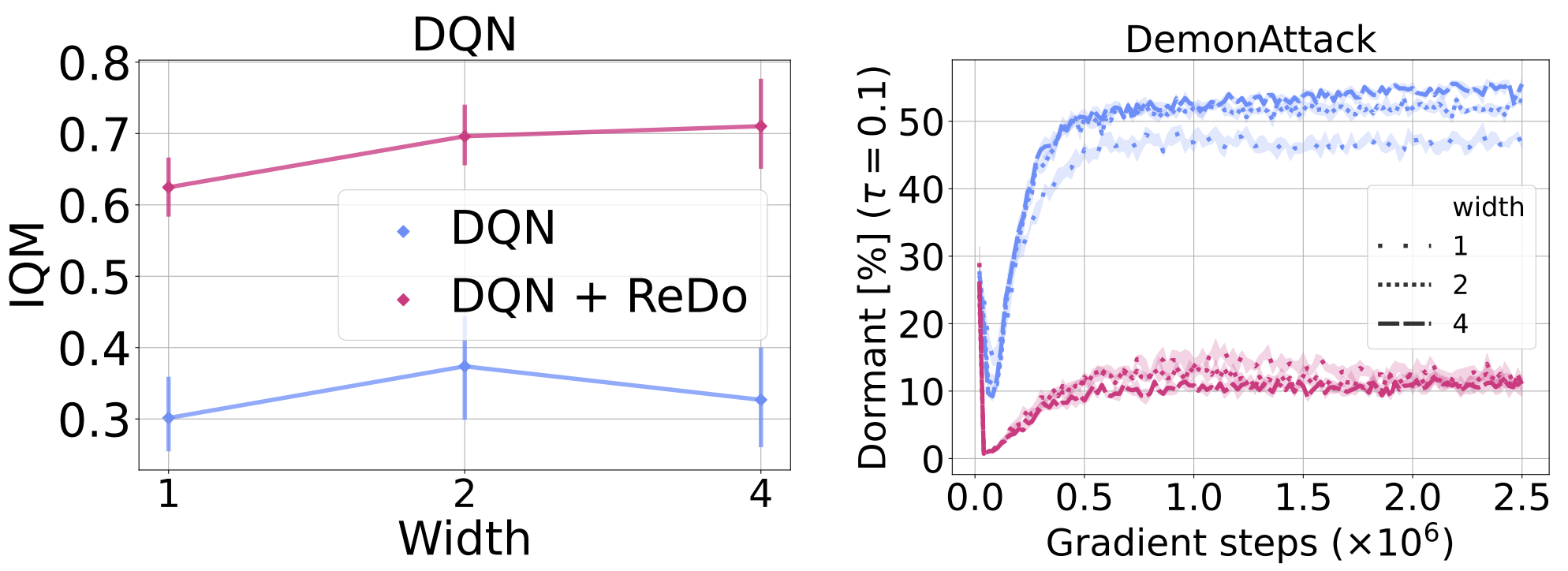
To investigate whether over-parameterization can mitigate the dormant neuron phenomenon, we increase the size of the DQN network by doubling and quadrupling the width of its layers (both the convolutional and fully connected). The left plot in Figure 12 shows that larger networks have at most a mild positive effect on the performance of DQN, and the resulting performance is still far inferior to that obtained when using ReDo with the default width. Furthermore, training with ReDo seems to improve as the network size increases, suggesting that the agent is able to better exploit network parameters, compared to when training without ReDo.
An interesting finding in the figure below is that the percentage of dormant neurons is similar across the varying widths. As expected, the use of ReDo dramatically reduces this number for all values.
Comparison to other methods
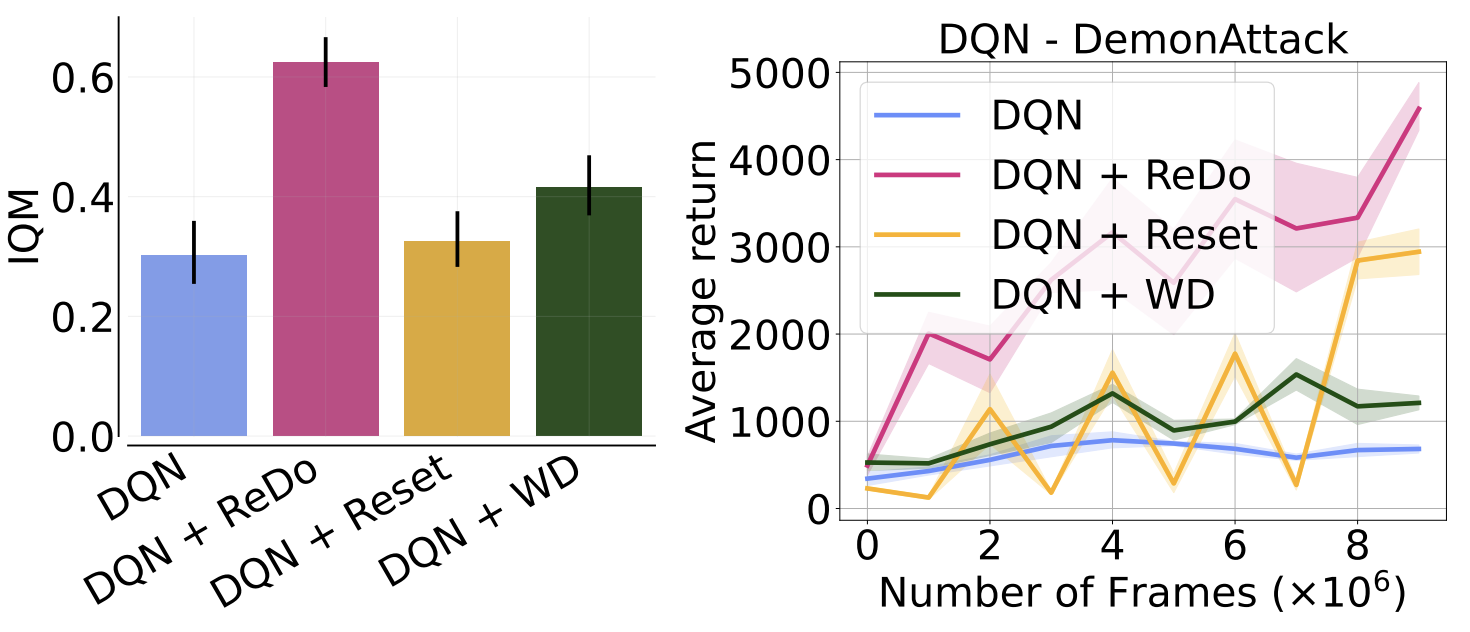
Nikishin et al. (2022) also observed performance collapse when increasing the replay ratio, but attributed this to overfitting to early samples (an effect they refer to as the “primacy bias”). To mitigate this, they proposed periodically resetting the network, which can be seen as a form of regularization. We compare the performance of ReDo against theirs, which periodically resets only the penultimate layer for Atari environments. Additionally, we compare to adding weight decay, as this is a simpler, but related, form of regularization. It is worth highlighting that Nikishin et al. (2022) also found high values of replay ratio to be more amenable to their method. As the figure below illustrates, weight decay is comparable to periodic resets, but ReDo is superior to both.
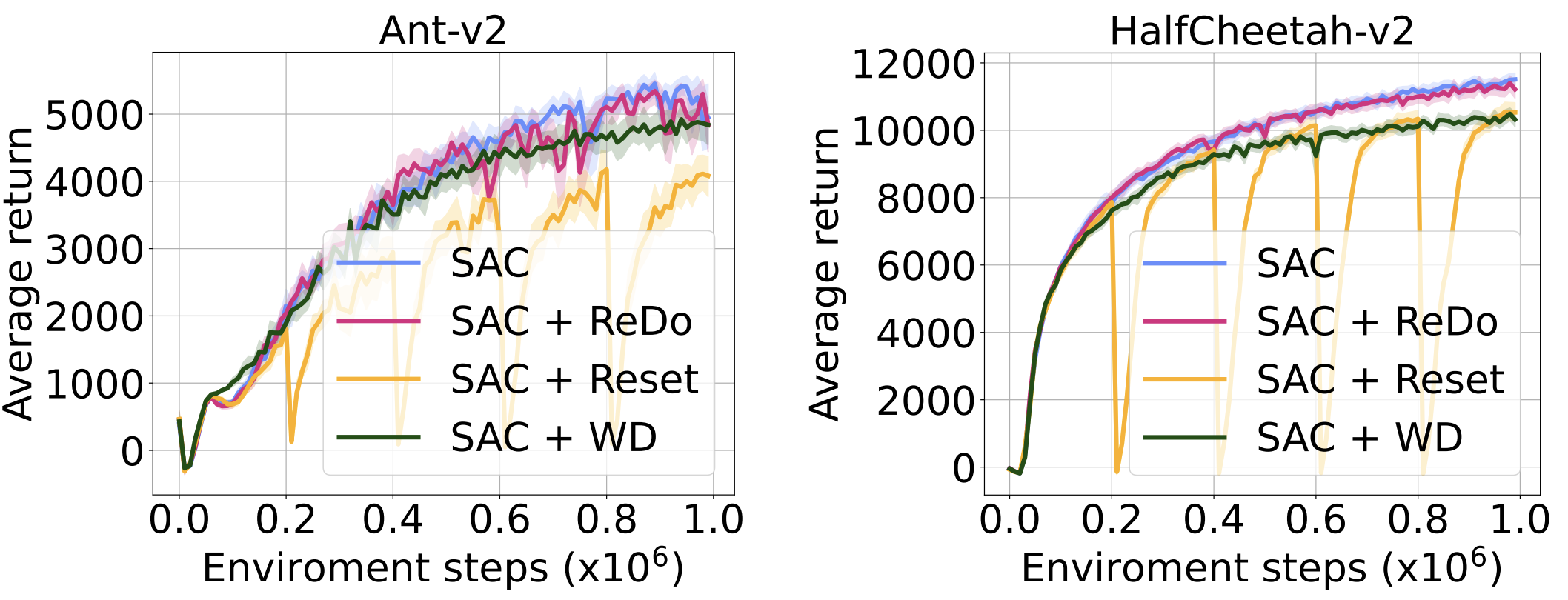
We continue our comparison with resets and weight decay on two MuJoCo environments with the SAC agent. As the figure below shows, ReDo is the only method that does not suffer a performance degradation.
Discussion and Conclusion
In this work we identified the dormant neuron phenomenon whereby, during training, an RL agent’s neural network exhibits an increase in the number of neurons with littleor-no activation. We demonstrated that this phenomenon is present across a variety of algorithms and domains, and provided evidence that it does result in reduced expressivity and inability to adapt to new tasks.
Interestingly, studies in neuroscience have found similar types of dormant neurons (precursors) in the adult brain of several mammalian species, including humans, albeit with different dynamics. Certain brain neurons start off as dormant during embryonic development, and progressively awaken with age, eventually becoming mature and functionally integrated as excitatory neurons. Contrastingly, the dormant neurons we investigate here emerge over time and exacerbate with more gradient updates.
To overcome this issue, we proposed a simple method (ReDo) to maintain network utilization throughout training by periodic recycling of dormant neurons. The simplicity of ReDo allows for easy integration with existing RL algorithms. Our experiments suggest that this can lead to improved performance. Indeed, our results suggest that ReDo can be an important component in being able to successfully scale RL networks in a sample-efficient manner.
Limitations and future work
Although the simple approach of recycling neurons we introduced yielded good results, it is possible that better approaches exist. For example, ReDo reduces dormant neurons significantly but it doesn’t completely eliminate them. Further research on initialization and optimization of the recycled capacity can address this and lead to improved performance. Additionally, the dormancy threshold is a hyperparameter that requires tuning; having an adaptive threshold over the course of training could improve performance even further. Finally, further investigation into the relationship between the task’s complexity, network capacity, and the dormant neuron phenomenon would provide a more comprehensive understanding.
This work suggests there are important gains to be had by investigating the network architectures and topologies used for deep reinforcement learning. Moreover, the observed network’s behavior during training (i.e. the change in the network capacity utilization), which differs from supervised learning, indicates a need to explore optimization techniques specific to reinforcement learning due to its unique learning dynamics.
comments powered by Disqus