
Pablo Samuel Castro
December 16, 2020
2020 RL highlights
As part of TWiML ’s AI Rewind series, I was asked to provide a list of reinforcement learning papers that were highlights for me in 2020. It’s been a difficult year for pretty much everyone, but it’s heartening to see that despite all the difficulties, interesting research still came out.
Given the size and breadth of the reinforcement learning research, as well as the fact that I was asked to do this at the end of NeurIPS and right before my vacation, I decided to apply the following rules in the selection:
- Select only papers published in AAAI, ICLR, ICML, or NeurIPS. Like any good rule, there are a few exceptions :).
- Select papers only from areas where I’m most actively doing research. The last section is an exception to this rule.
Due to time constraints, my process of selection was most likely not the best; if you feel there are papers I’m omitting here, send them my way and I may add them. They are also presented here in no particular order, and for most I provide only a brief synposis taken from the papers themselves. Unless written in auburn colour, all texts below are taken from the source papers.
You can get more details in the TWiML post, or listen to it directly here:
After having laid out all those disclaimers, hope this list proves useful!
Metrics / Representations
One of my most active areas of research is investigating how to build good representations for learning. While there is no clear, and globally accepted, definition of what it means to have a good representation, what I take it to mean is:
- Has lower dimensionality than the original state space
- Can be learned concurrently while policies are being improved upon
- Can generalize well to unseen states
- Has well-developed theoretical properties
I first begin with some theoretical papers related to representation learning, and then I continue with metrics. I am of the belief that state (or state-action) metrics can help us with the last point and, if done carefully, can yield the other points as well. I begin with some papers that deal with state similarity measures, and transition into more “traditional” representation learning papers, which mostly make use of contrastive losses.
Representations for Stable Off-Policy Reinforcement Learning
Dibya Ghosh, Marc G. Bellemare
We formally show that there are indeed nontrivial state representations under which the canonical TD algorithm is stable, even when learning off-policy. We analyze representation learning schemes that are based on the transition matrix of a policy, such as proto-value functions, along three axes: approximation error, stability, and ease of estimation. In the most general case, we show that a Schur basis provides convergence guarantees, but is difficult to estimate from samples. For a fixed reward function, we find that an orthogonal basis of the corresponding Krylov subspace is an even better choice.

Although positive-definite representations admit amenable optimization properties, such as invariance to reparametrization and monotonic convergence, they can only express value functions that satisfy a growth condition. Under on-policy sampling this growth condition is nonrestrictive, but as the policy deviates from the data distribution, the expressiveness of positive-definite representations reduces greatly.
Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?
Simon S. Du, Sham M. Kakade, Ruosong Wang, Lin F. Yang
Modern deep learning methods provide effective means to learn good representations. However, is a good representation itself sufficient for sample efficient reinforcement learning? Our main results provide sharp thresholds for reinforcement learning methods, showing that there are hard limitations on what constitutes good function approximation (in terms of the dimensionality of the representation), where we focus on natural representational conditions relevant to value-based, model-based, and policy-based learning. These lower bounds highlight that having a good (value-based, model-based, or policy-based) representation in and of itself is insufficient for efficient reinforcement learning, unless the quality of this approximation passes certain hard thresholds. Furthermore, our lower bounds also imply exponential separations on the sample complexity between 1) value-based learning with perfect representation and value-based learning with a good-but-not-perfect representation, 2) value-based learning and policy-based learning, 3) policy-based learning and supervised learning and 4) reinforcement learning and imitation learning.

Scalable methods for computing state similarity in deterministic MDPs
Pablo Samuel Castro
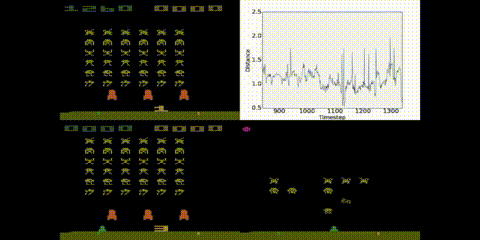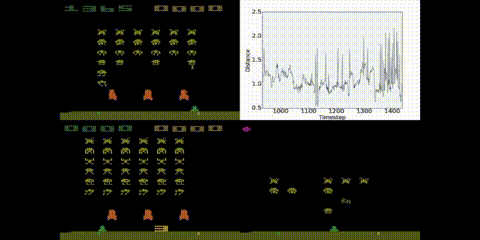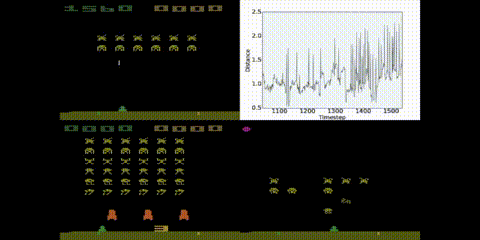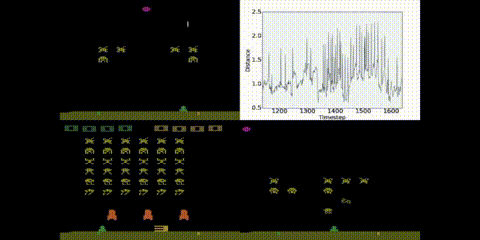 Bisimulation metrics have some very pleasing theoretical properties, but are very expensive to compute and, until this year, were considered impractical for systems with very large (or continuous) state spaces. In this paper (published at AAAI) I introduce a mechanism for approximating these metrics using deep networks, even when we have large environments like Atar 2600 games, as long as transitions are deterministic.
Bisimulation metrics have some very pleasing theoretical properties, but are very expensive to compute and, until this year, were considered impractical for systems with very large (or continuous) state spaces. In this paper (published at AAAI) I introduce a mechanism for approximating these metrics using deep networks, even when we have large environments like Atar 2600 games, as long as transitions are deterministic.
You can read all about it in my post.
Learning Invariant Representations for Reinforcement Learning without Reconstruction
Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, Sergey Levine
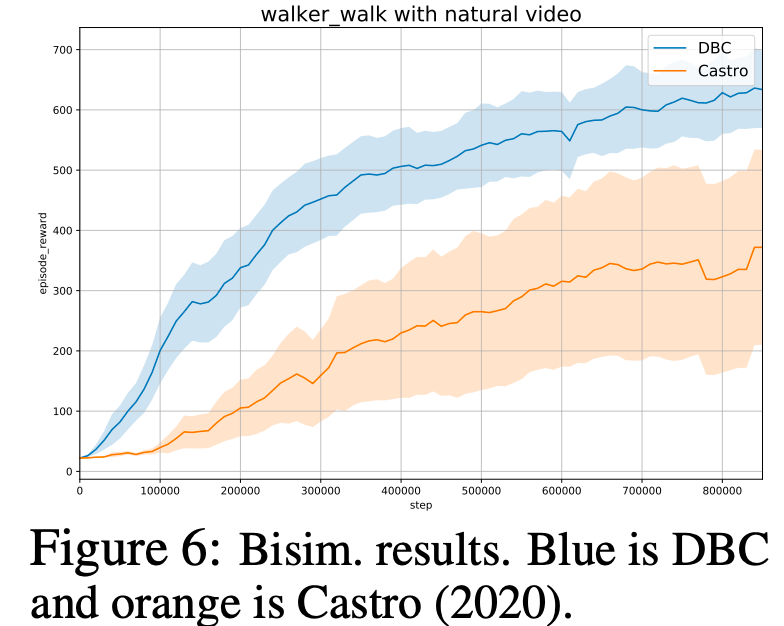
This paper has not been published in a peer-reviewed conference ([yet!](https://openreview.net/forum?id=-2FCwDKRREu)), but I include it here as it is a really nice followup to my AAAI paper just mentioned. They introduce Deep Bisimulation for Control (DBC), which aims to learn latent encodings whose $\ell_1$ distance respects the bisimulation metric.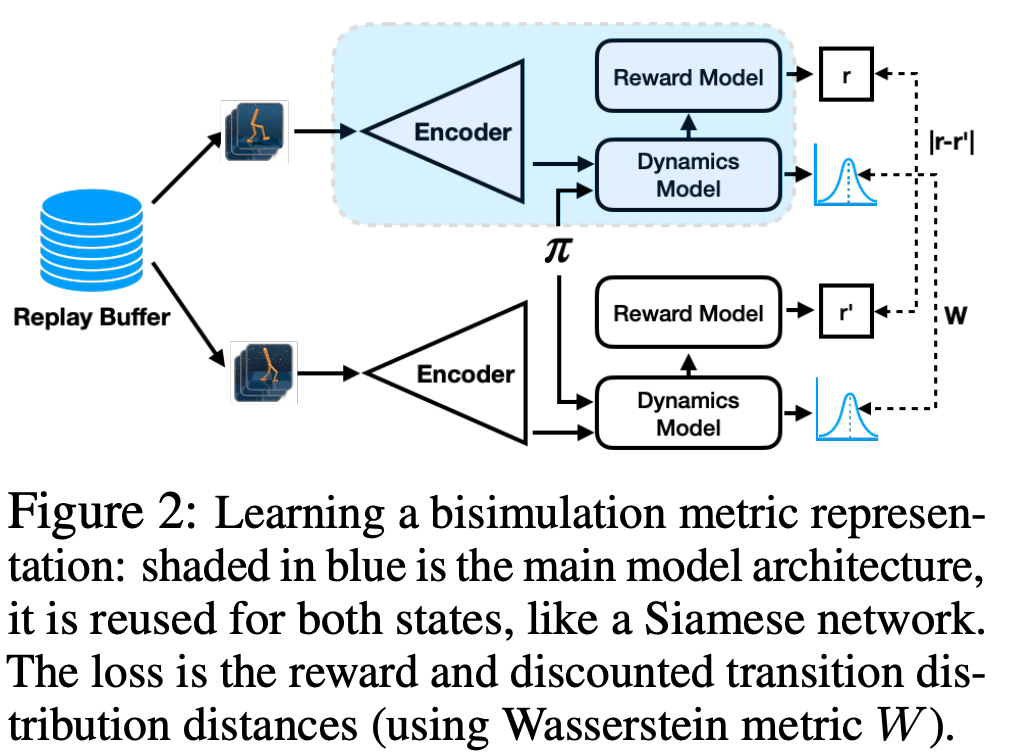 They overcome the deterministic assumption I had to make by noticing that if transitions are Gaussian, the 2-Wasserstein metric can be expressed in closed form. One of the things I really enjoyed about this paper is seeing my loss being used successfully for control (although their DBC proposal achieves better performance).
They overcome the deterministic assumption I had to make by noticing that if transitions are Gaussian, the 2-Wasserstein metric can be expressed in closed form. One of the things I really enjoyed about this paper is seeing my loss being used successfully for control (although their DBC proposal achieves better performance).
Dynamical Distance Learning for Semi-Supervised and Unsupervised Skill Discovery
Kristian Hartikainen, Xinyang Geng, Tuomas Haarnoja, Sergey Levine
We study how we can automatically learn dynamical distances: a measure of the expected number of time steps to reach a given goal state from any other state. These dynamical distances can be used to provide well-shaped reward functions for reaching new goals, making it possible to learn complex tasks efficiently. We show that our method can learn to turn a valve with a real-world 9-DoF hand, using raw image observations and just ten preference labels, without any other supervision.
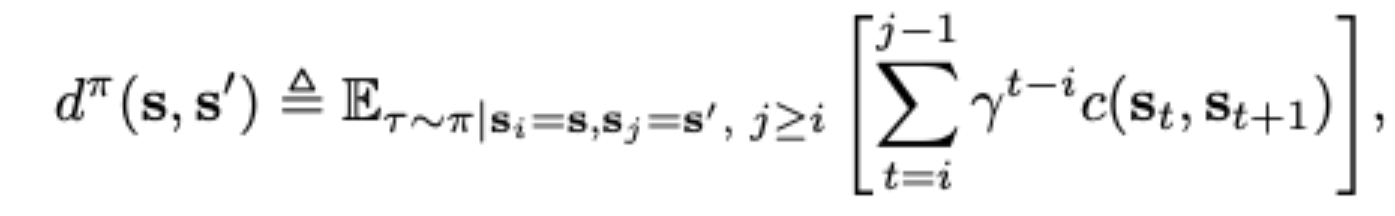

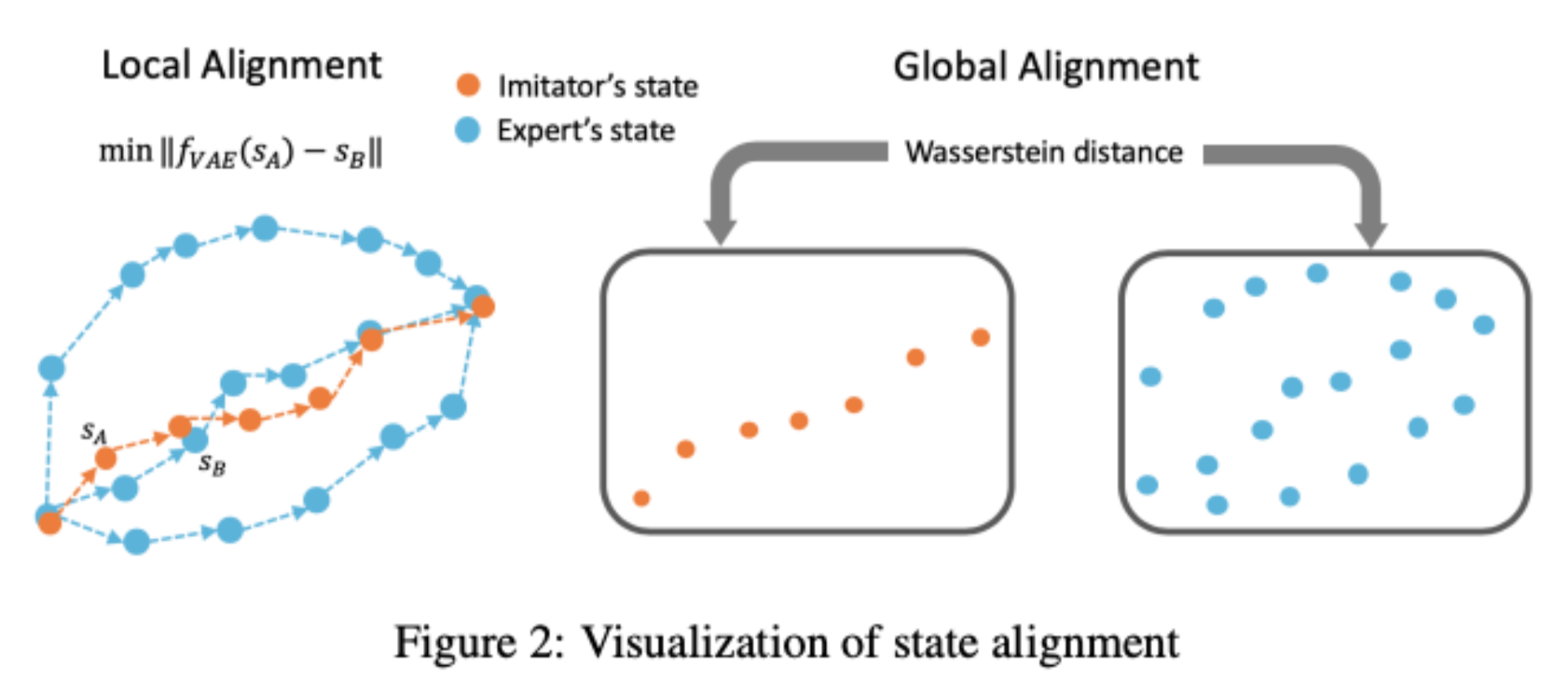
State Alignment-based Imitation Learning
Fangchen Liu, Zhan Ling, Tongzhou Mu, Hao Su
We propose a novel state alignment based imitation learning method to train the imitator to follow the state sequences in expert demonstrations as much as possible. The state alignment comes from both local and global perspectives and we combine them into a reinforcement learning framework by a regularized policy update objective.
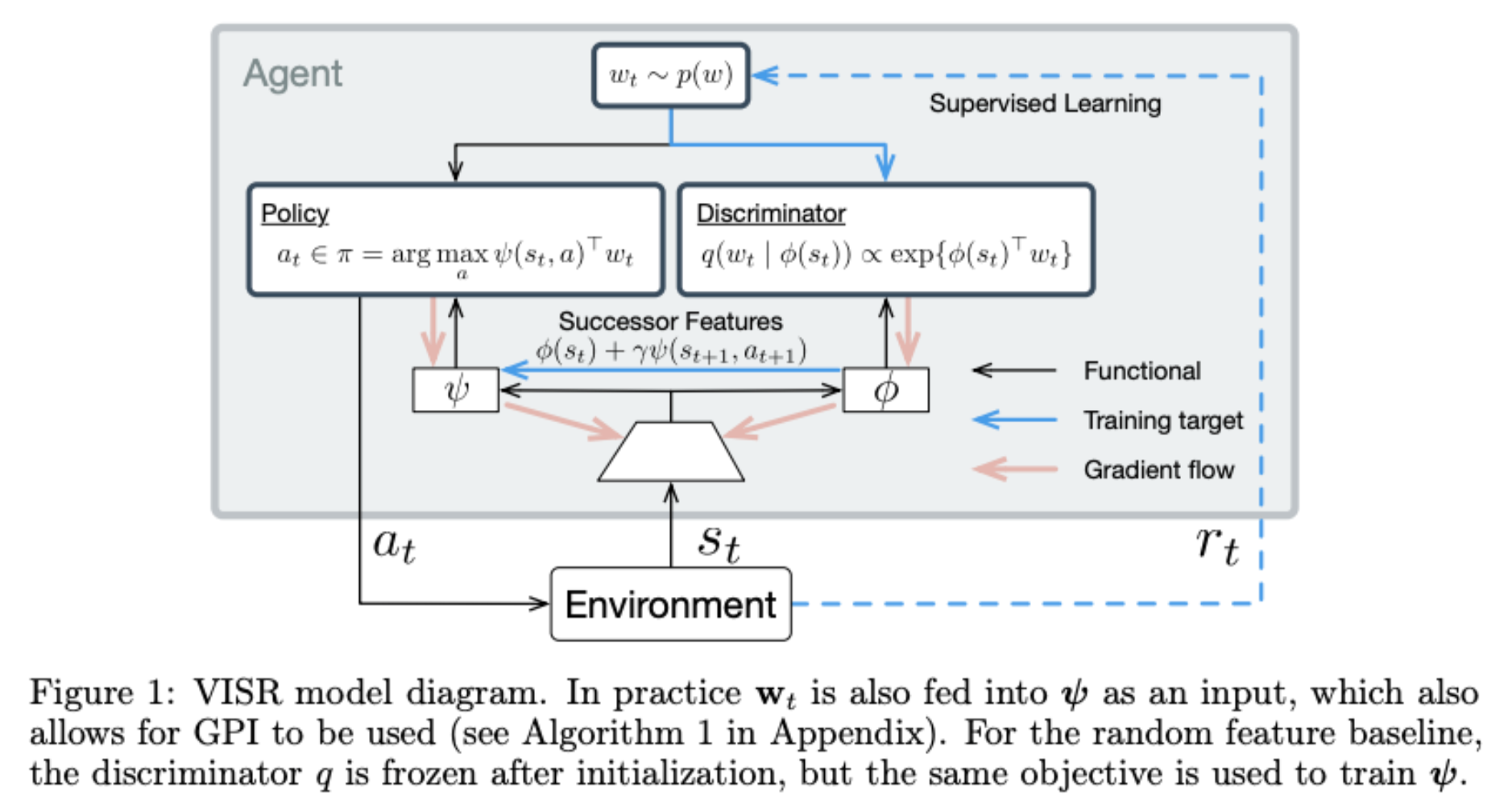
Fast Task Inference with Variational Intrinsic Successor Features
Steven Hansen, Will Dabney, Andre Barreto, David Warde-Farley, Tom Van de Wiele, Volodymyr Mnih
It has been established that diverse behaviors spanning the controllable subspace of a Markov decision process can be trained by rewarding a policy for being distinguishable from other policies (Gregor et al., 2016; Eysenbach et al., 2018; Warde-Farley et al., 2018). However, one limitation of this formulation is the difficulty to generalize beyond the finite set of behaviors being explicitly learned, as may be needed in subsequent tasks. Successor features (Dayan, 1993; Barreto et al., 2017) provide an appealing solution to this generalization problem, but require defining the reward function as linear in some grounded feature space. In this paper, we show that these two techniques can be combined, and that each method solves the other’s primary limitation. To do so we introduce Variational Intrinsic Successor FeatuRes (VISR), a novel algorithm which learns controllable features that can be leveraged to provide enhanced generalization and fast task inference through the successor features framework.
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
Rishabh Agarwal, Marlos C. Machado, Pablo Samuel Castro, Marc G. Bellemare
This is another exemption to the first rule mentioned, but it was accepted and presented at the latest NeurIPS Deep RL workshop (poster) and the Workshop on Biological and Artificial RL (oral). We introduce the Policy Similarity Metric (PSM), which is based on bisimulation metrics but which replaces the differences in reward between states with the difference in optimal policies. This new metric is the reward-agnostic and can yield better generalization. We use this metric to introduce a new contrastive loss for learning representations: Policy Similarity Embeddings (PSEs). We demonstrate the effectiveness of this method on a number of challenging tasks.
You can read more details in Rishabh’s blog post.
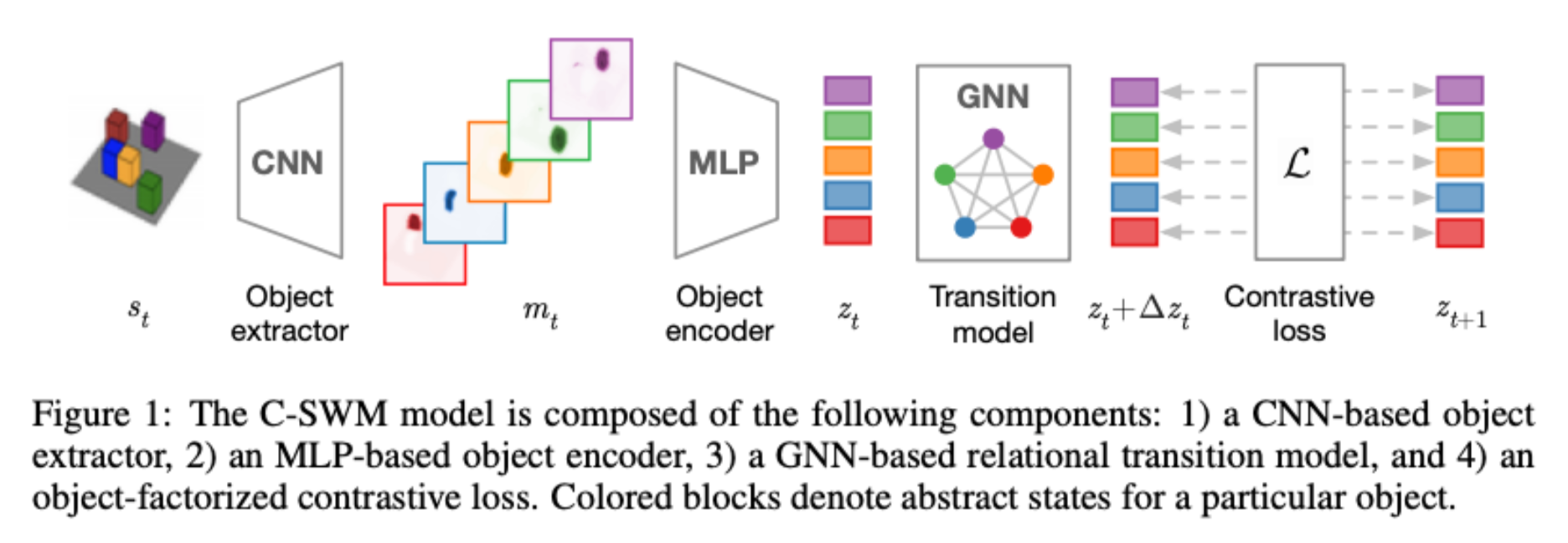
Contrastive Learning of Structured World Models
Thomas Kipf, Elise van der Pol, Max Welling
CSWMs utilize a contrastive approach for representation learning in environments with compositional structure. We structure each state embedding as a set of object representations and their relations, modeled by a graph neural network. This allows objects to be discovered from raw pixel observations without direct supervision as part of the learning process. We evaluate C-SWMs on compositional environments involving multiple interacting objects that can be manipulated independently by an agent, simple Atari games, and a multi-object physics simulation.
Our formulation of C-SWMs does not take into account stochasticity in environment transitions or observations, and hence is limited to fully deterministic worlds.
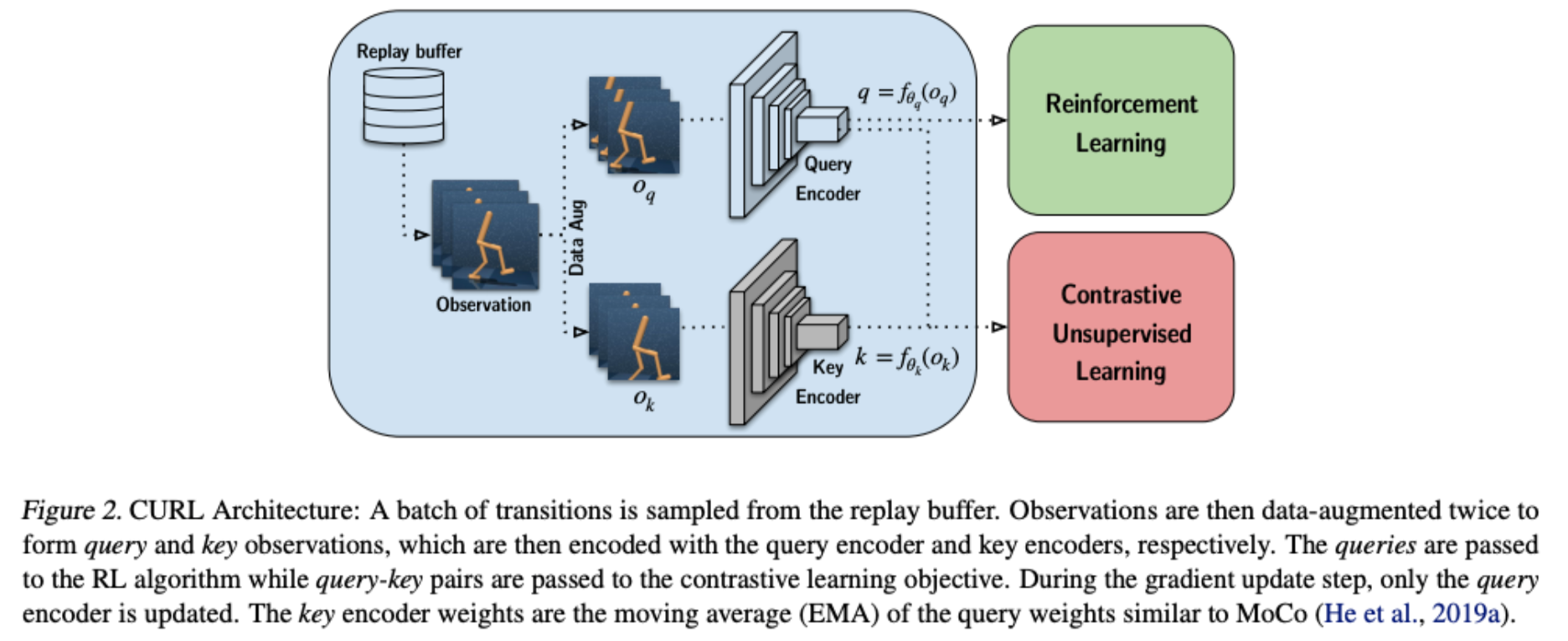
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Michael Laskin, Aravind Srinivas, Pieter Abbeel
CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features.
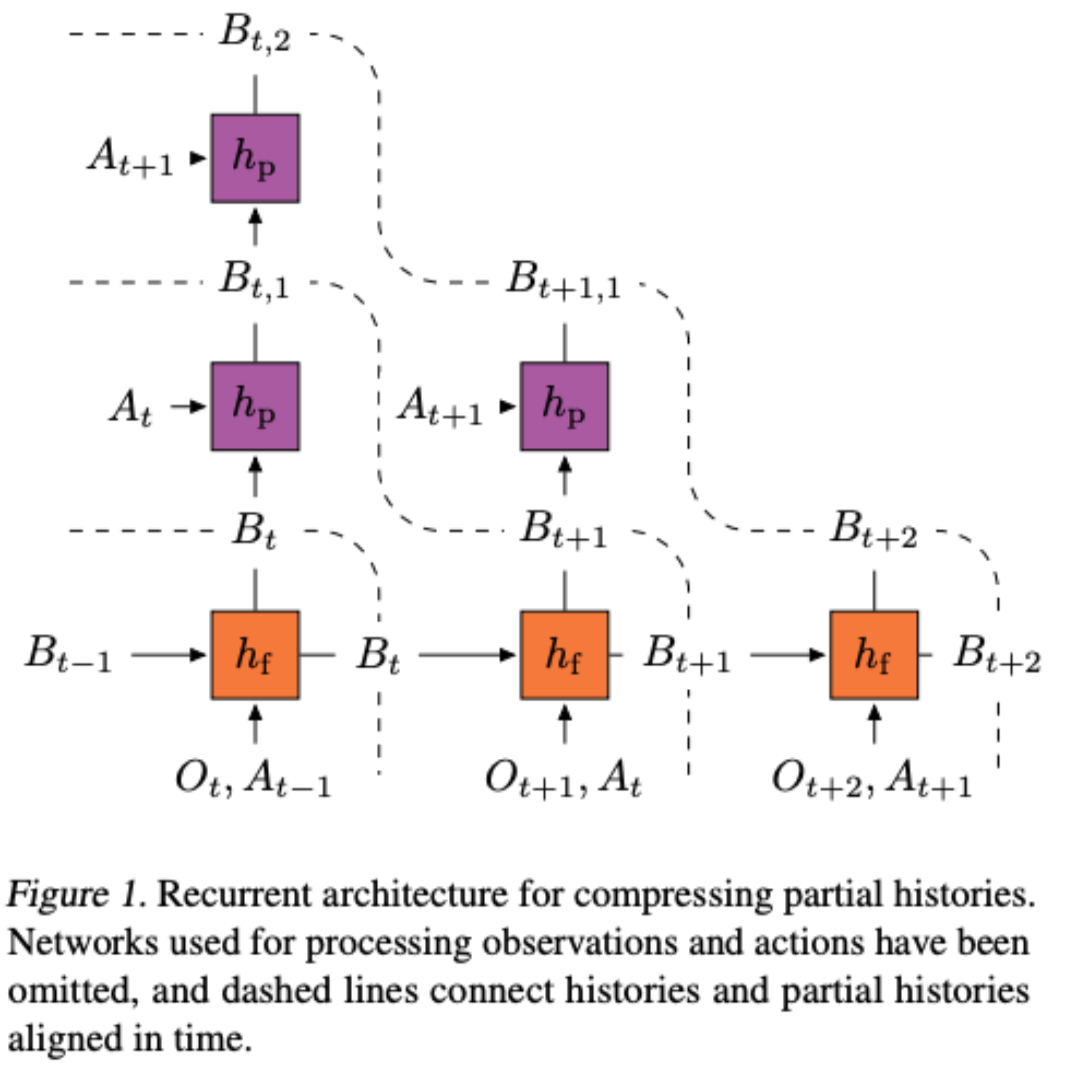
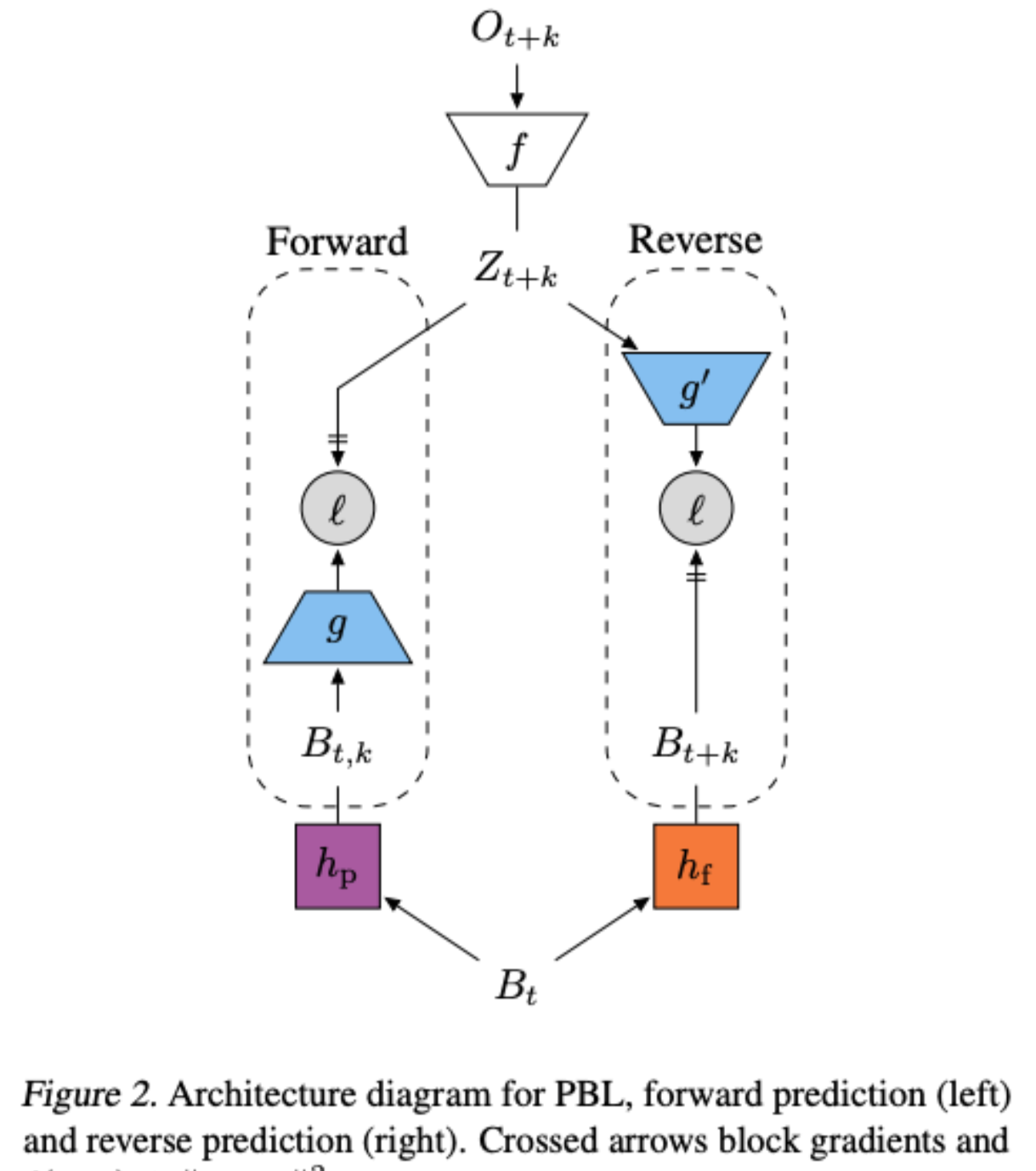
Bootstrap Latent-Predictive Representations for Multitask Reinforcement Learning
Zhaohan Daniel Guo, Bernardo Avila Pires, Bilal Piot, Jean-Bastien Grill, Florent Altché, Remi Munos, Mohammad Gheshlaghi Azar
PBL builds on multistep predictive representations of future observations, and focuses on capturing structured information about environment dynamics. Specifically, PBL trains its representation by predicting latent embeddings of future observations. These latent embeddings are themselves trained to be predictive of the aforementioned representations. These predictions form a bootstrapping effect, allowing the agent to learn more about the key aspects of the environment dynamics. In addition, by defining prediction tasks completely in latent space, PBL provides the flexibility of using multimodal observations involving pixel images, language instructions, rewards and more.
Planning to Explore via Self-Supervised World Models
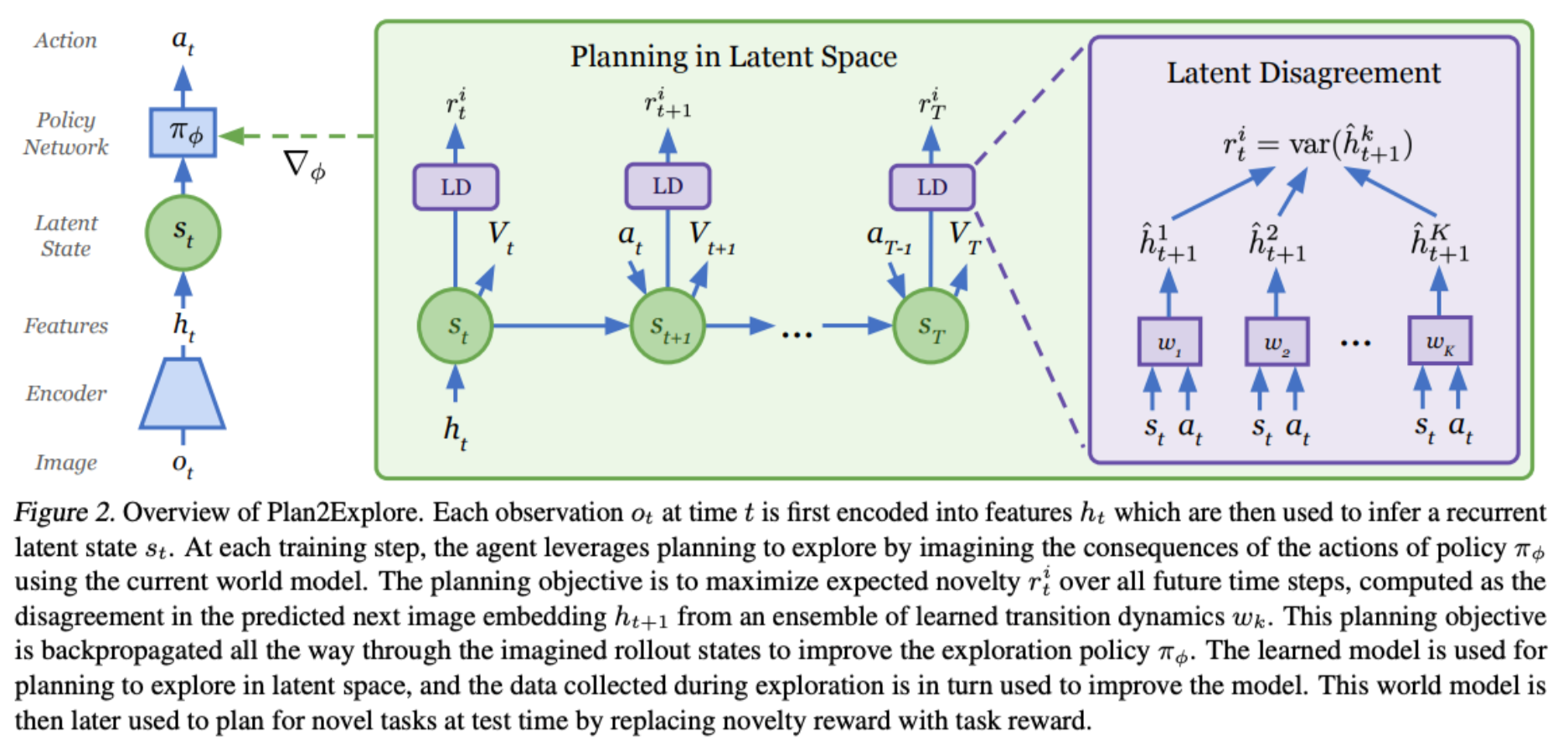
Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, Deepak Pathak
We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner.
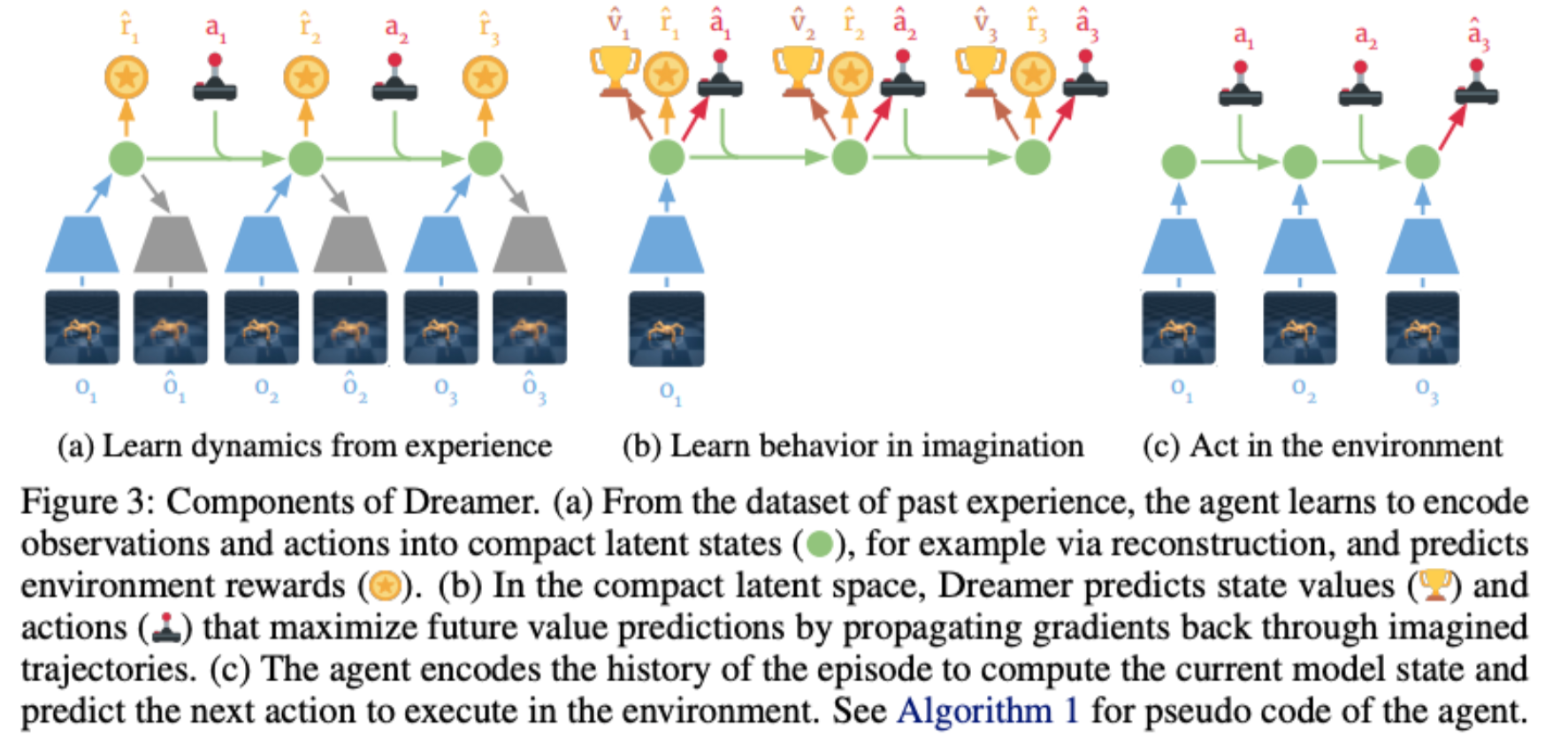
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, Mohammad Norouzi
We present Dreamer, a reinforcement learning agent that solves long-horizon tasks from images purely by latent imagination. We efficiently learn behaviors by propagating analytic gradients of learned state values back through trajectories imagined in the compact state space of a learned world model.
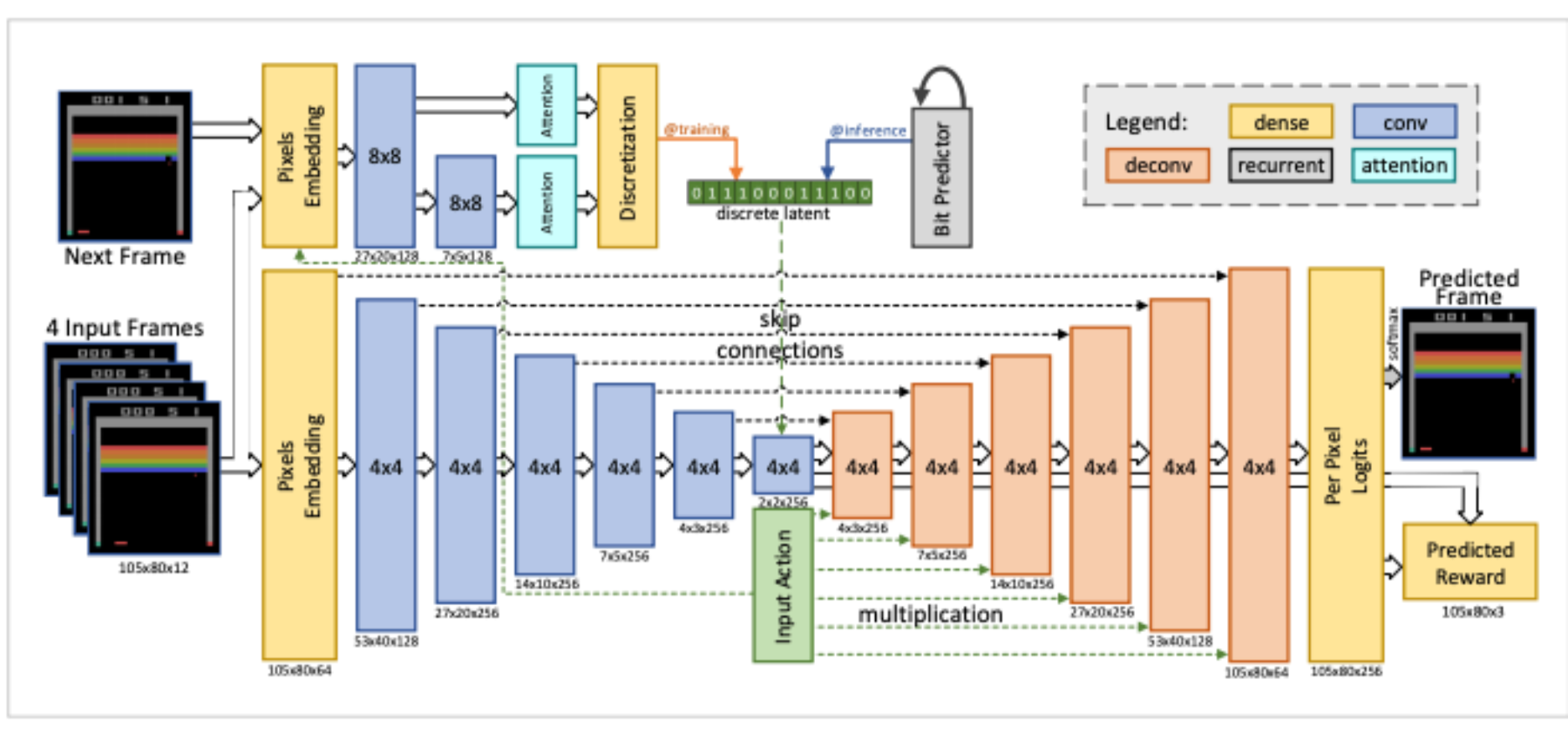
Model Based Reinforcement Learning for Atari
Łukasz Kaiser, Mohammad Babaeizadeh, Piotr Miłos, Błażej Osiński, Roy H Campbell, Konrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozakowski, Sergey Levine, Afroz Mohiuddin, Ryan Sepassi, George Tucker, Henryk Michalewski
We explore how video prediction models can similarly enable agents to solve Atari games with fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting.
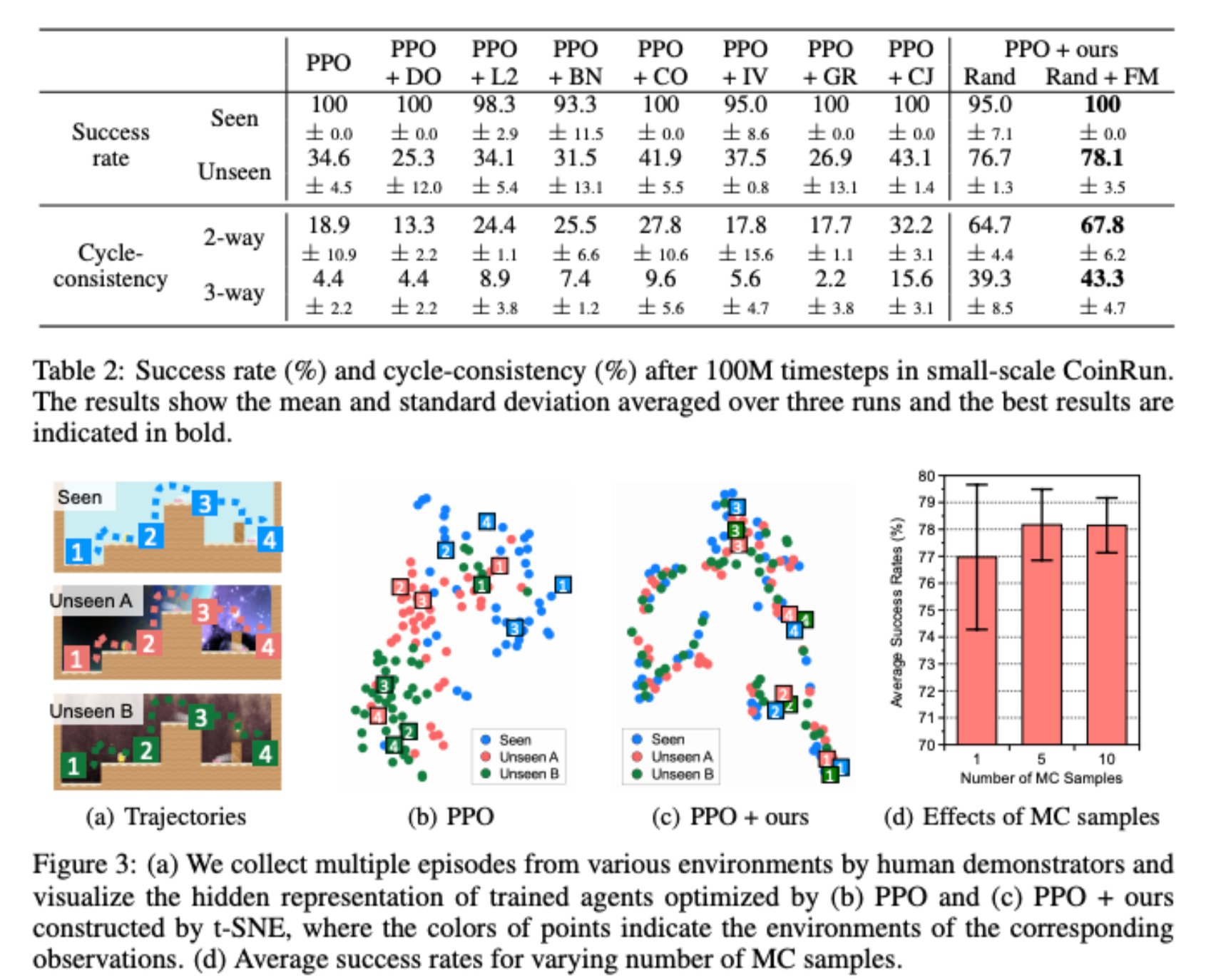
Network Randomization: A Simple Technique for Generalization in Deep Reinforcement Learning
Kimin Lee, Kibok Lee, Jinwoo Shin, Honglak Lee
We propose a simple technique to improve a generalization ability of deep RL agents by introducing a randomized (convolutional) neural network that randomly perturbs input observations. It enables trained agents to adapt to new domains by learning robust features invariant across varied and randomized environments. Furthermore, we consider an inference method based on the Monte Carlo approximation to reduce the variance induced by this randomization.
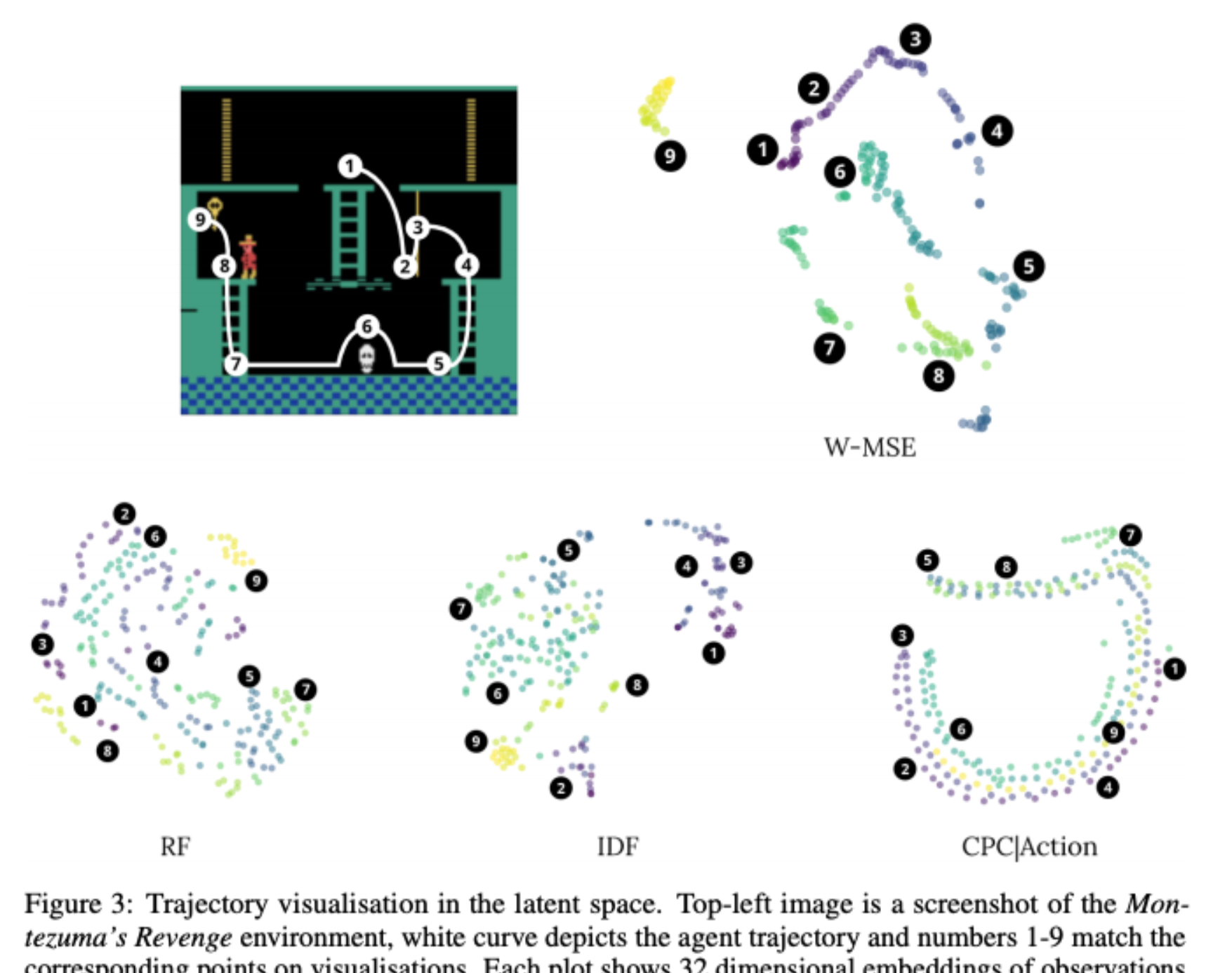
Latent World Models For Intrinsically Motivated Exploration
Aleksandr Ermolov, Nicu Sebe
We present a self-supervised representation learning method for image-based observations, which arranges embeddings respecting temporal distance of observations. This representation is empirically robust to stochasticity and suitable for novelty detection from the error of a predictive forward model. We consider episodic and life-long uncertainties to guide the exploration. We propose to estimate the missing information about the environment with the world model, which operates in the learned latent space.
Understanding / evaluating deep RL
I have become very interested in getting a better understanding of how deep networks interact with reinforcement learning. Most of the theory we have is limited to linear function approximators, but it is become increasingly evident that the, often overlooked, design decisions taken when setting up experiments can have a dramatic effect on performance.
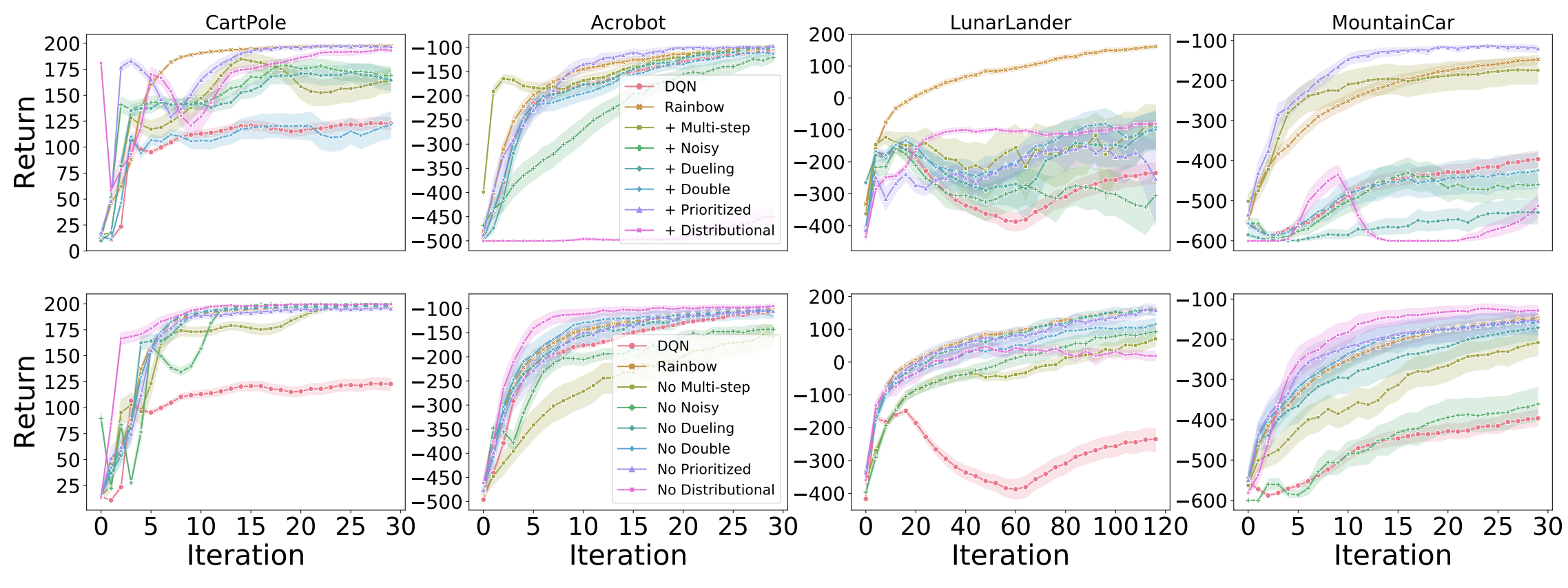
Revisiting Rainbow
Johan S. Obando-Ceron and Pablo Samuel Castro
I begin with another exception to the first rule. This is a paper we presented at the latest NeurIPS deep RL workshop. In it, we argue for the value of small- to mid-scale environments in deep RL for increasing scientific insight and help make our community more inclusive.
You can read all the details in my blog post.
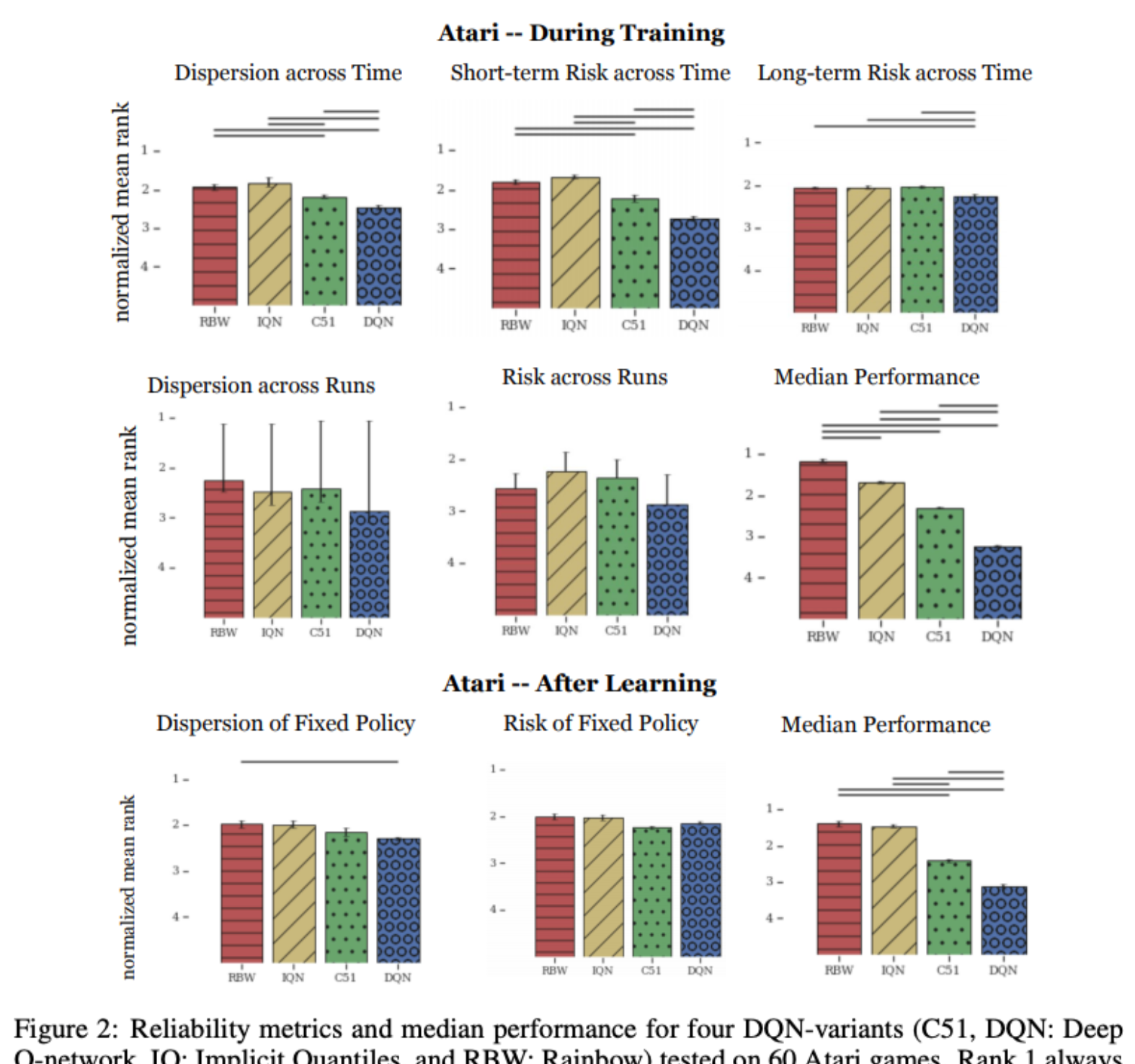
Measuring the Reliability of Reinforcement Learning Algorithms
Stephanie C.Y. Chan, Samuel Fishman, Anoop Korattikara, John Canny, Sergio Guadarrama
We propose a set of metrics that quantitatively measure different aspects of reliability. In this work, we focus on variability and risk, both during training and after learning (on a fixed policy). We designed these metrics to be general-purpose, and we also designed complementary statistical tests to enable rigorous comparisons on these metrics.
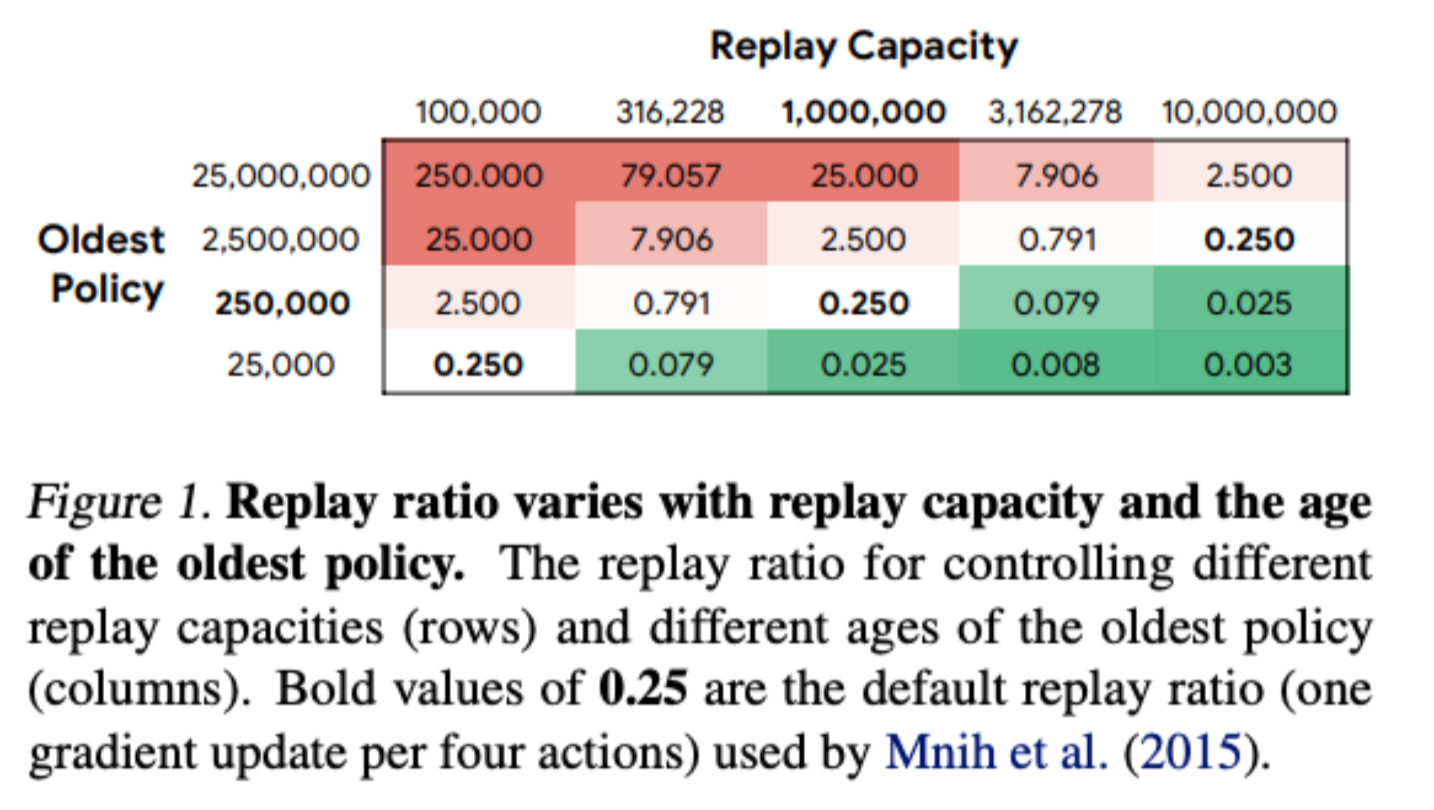
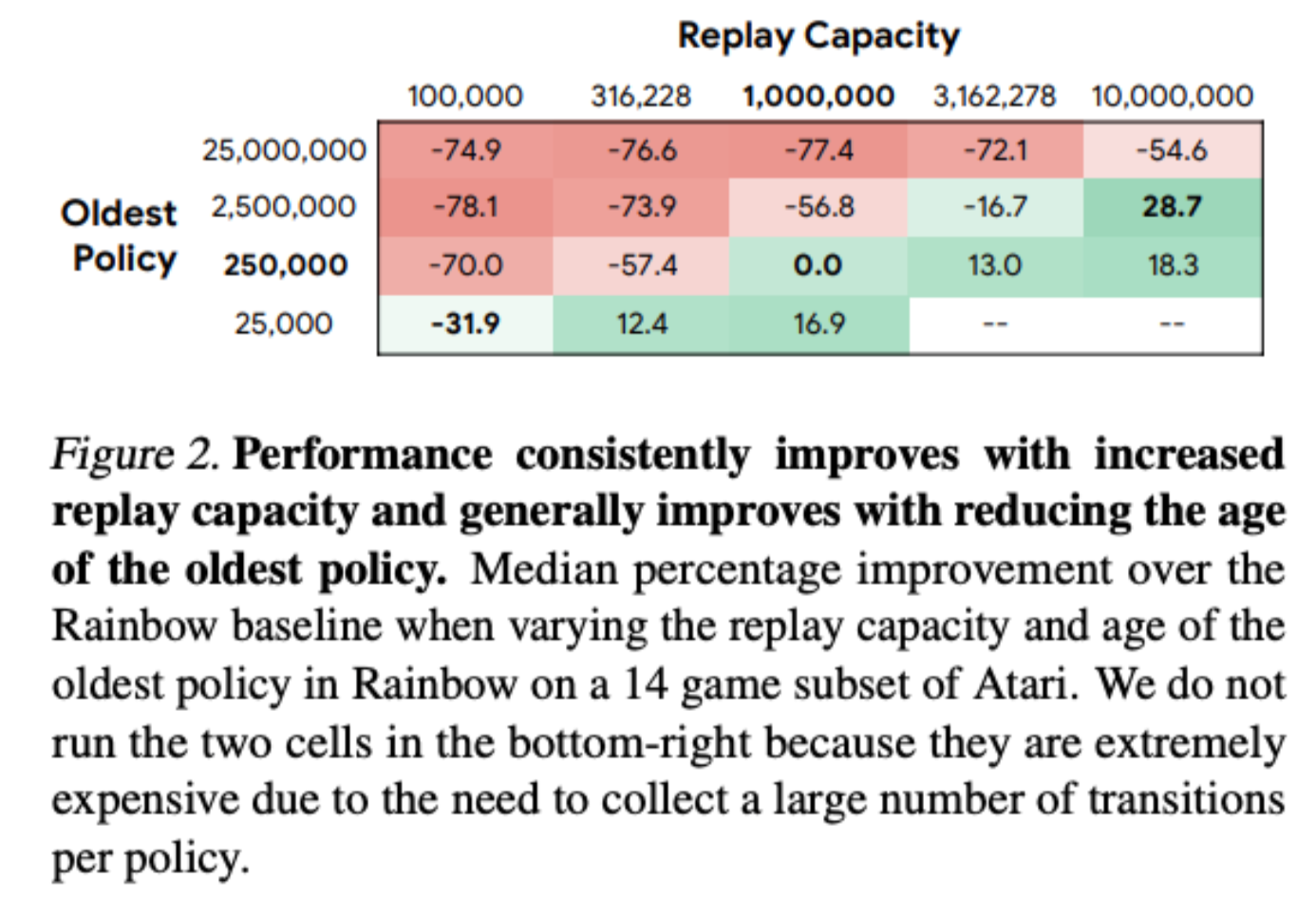
Revisiting Fundamentals of Experience Replay
William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, Will Dabney
We therefore present a systematic and extensive analysis of experience replay in Q-learning methods, focusing on two fundamental properties: the replay capacity and the ratio of learning updates to experience collected (replay ratio). Our additive and ablative studies upend conventional wisdom around experience replay — greater capacity is found to substantially increase the performance of certain algorithms, while leaving others unaffected. Counterintuitively we show that theoretically ungrounded, uncorrected n-step returns are uniquely beneficial while other techniques confer limited benefit for sifting through larger memory.
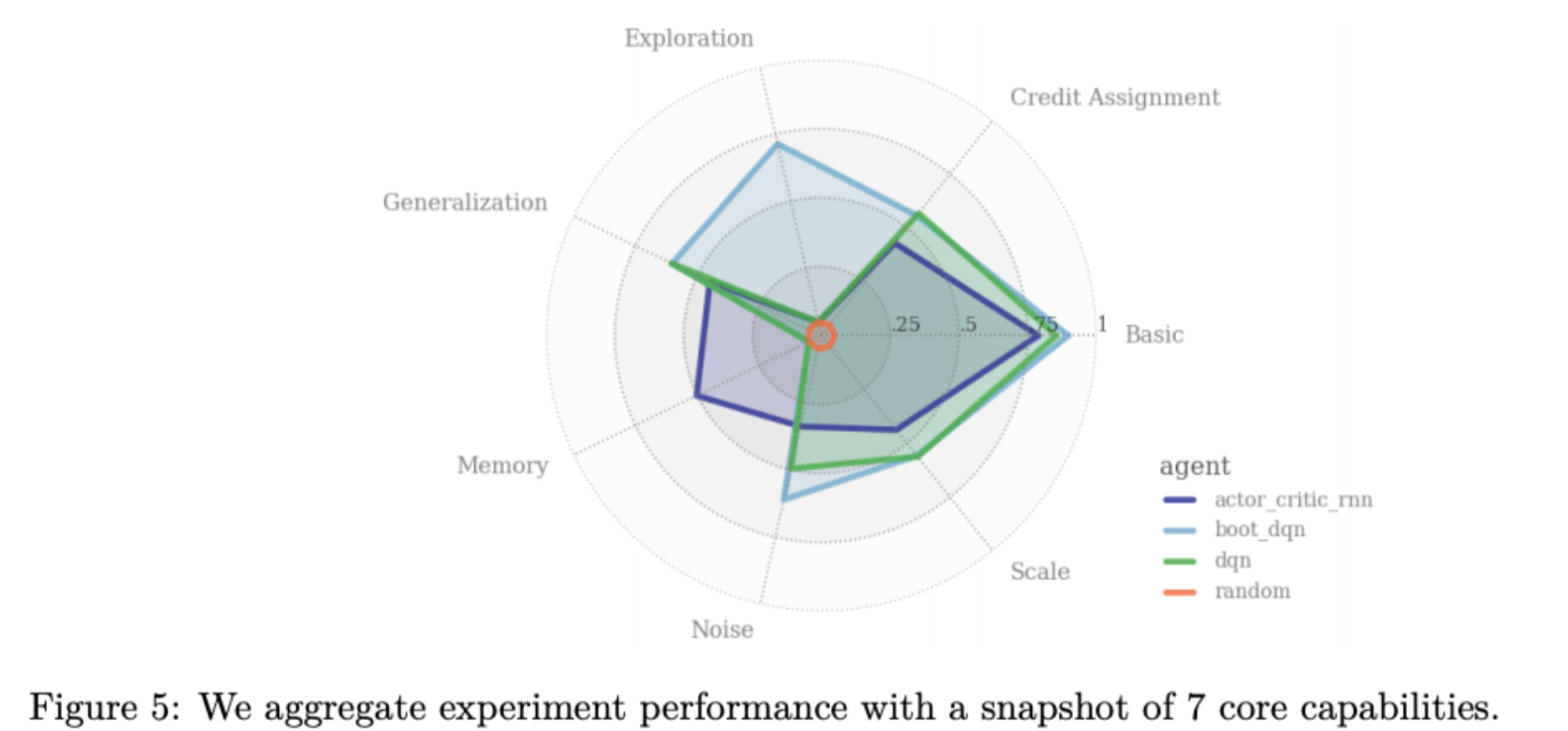
Behaviour Suite for Reinforcement Learning
Ian Osband, Yotam Doron, Matteo Hessel, John Aslanides, Eren Sezener, Andre Saraiva, Katrina McKinney, Tor Lattimore, Csaba Szepesvari, Satinder Singh, Benjamin Van Roy, Richard Sutton, David Silver, Hado Van Hasselt
This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks.
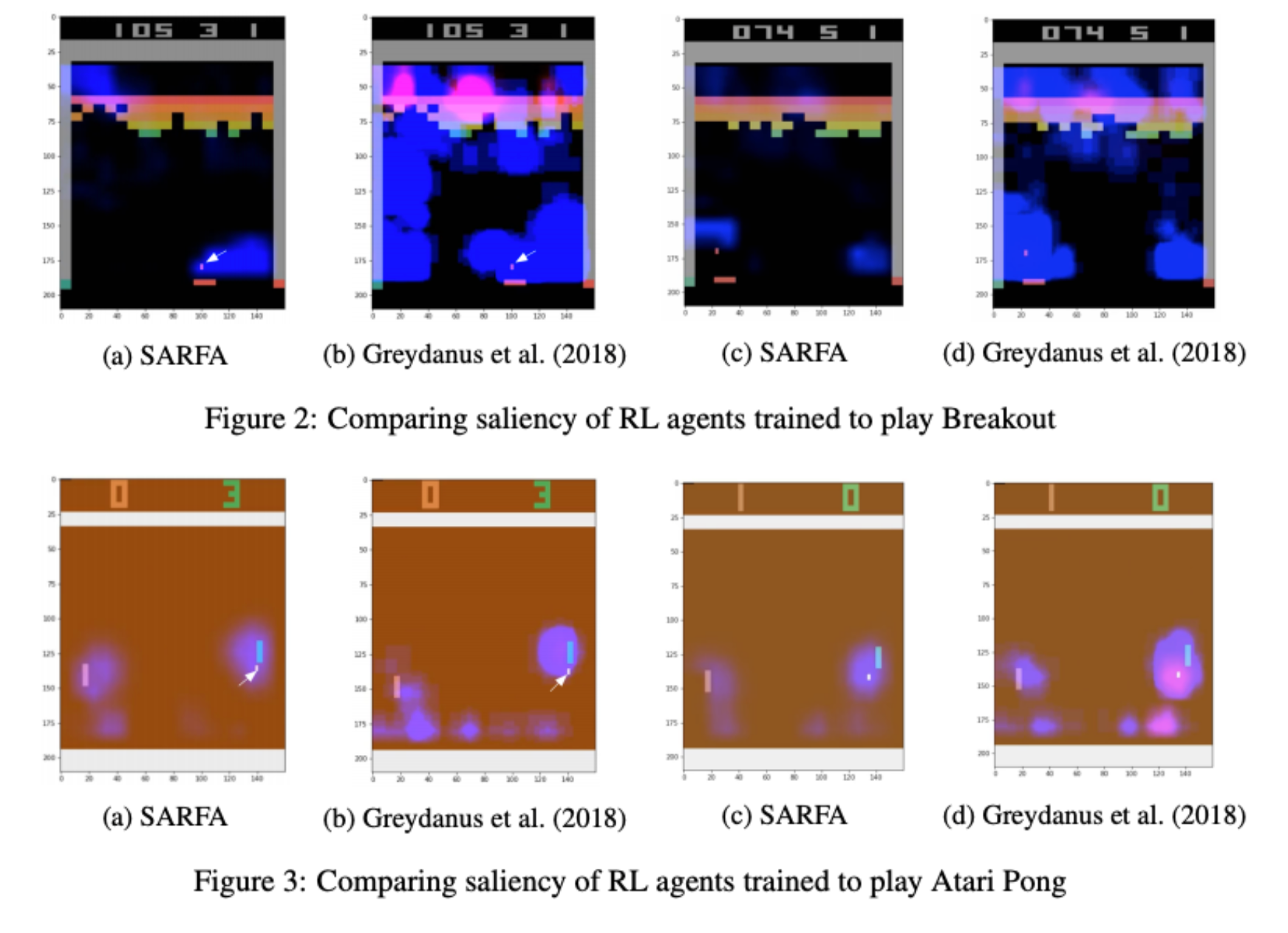
Explain Your Move: Understanding Agent Actions Using Specific and Relevant Feature Attribution
Nikaash Puri, Sukriti Verma, Piyush Gupta, Dhruv Kayastha, Shripad Deshmukh, Balaji Krishnamurthy, Sameer Singh
Our proposed approach, SARFA (Specific and Relevant Feature Attribution), generates more focused saliency maps by balancing two aspects (specificity and relevance) that capture different desiderata of saliency. The first captures the impact of perturbation on the relative expected reward of the action to be explained. The second downweighs irrelevant features that alter the relative expected rewards of actions other than the action to be explained.
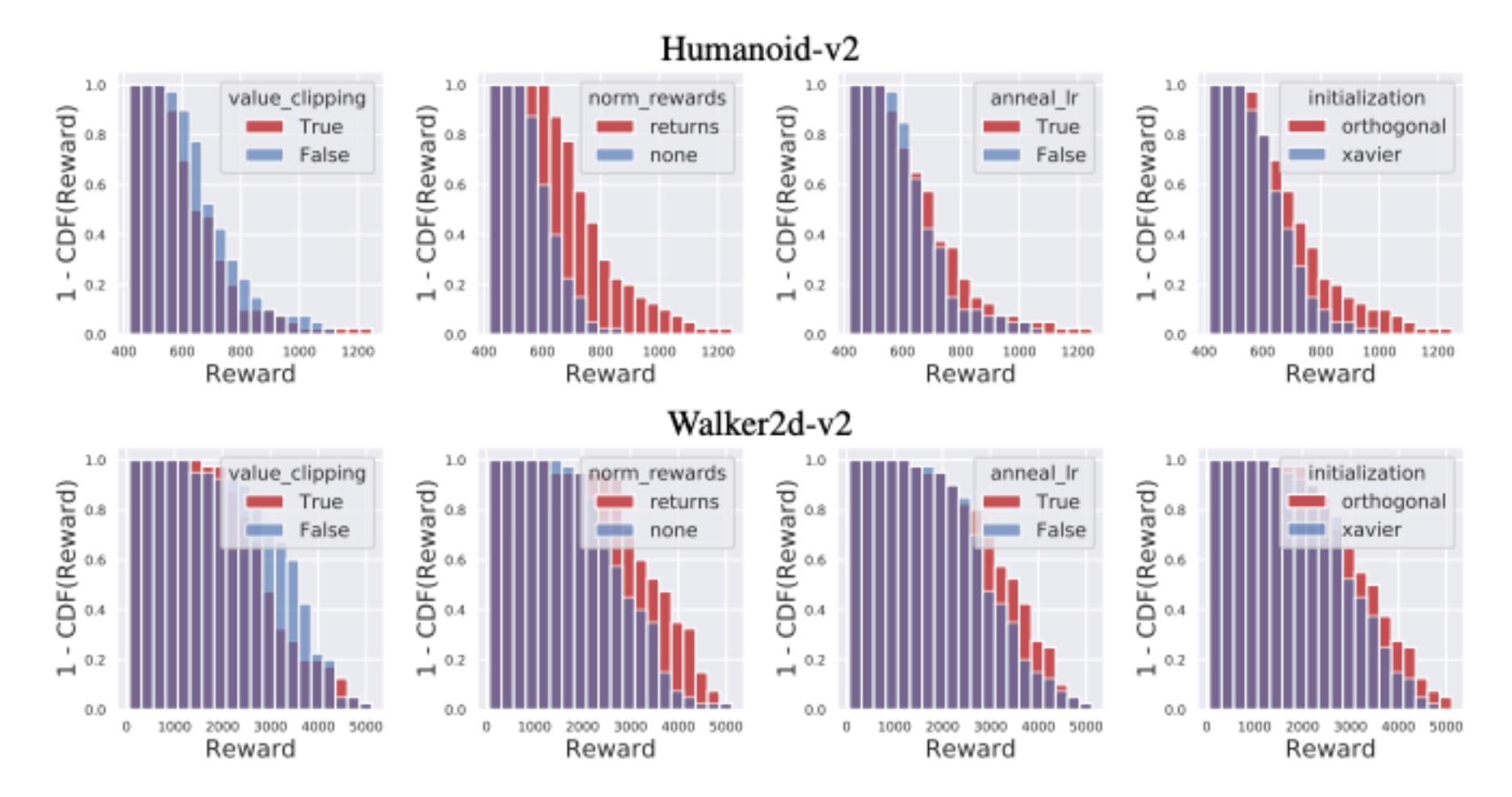
Implementation Matters in Deep RL: A Case Study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, Aleksander Madry
We investigate the consequences of “code-level optimizations:” algorithm augmentations found only in implementations or described as auxiliary details to the core algorithm. Seemingly of secondary importance, such optimizations turn out to have a major impact on agent behavior. Our results show that they (a) are responsible for most of PPO’s gain in cumulative reward over TRPO, and (b) fundamentally change how RL methods function.
RL in the real world
We are all ultimately working towards having our methods become useful in the real world. In this section I present three papers which do exactly this. I’m only including papers that I’m not just because I’m self-centered, but because I don’t follow this literature as well as I probably should.
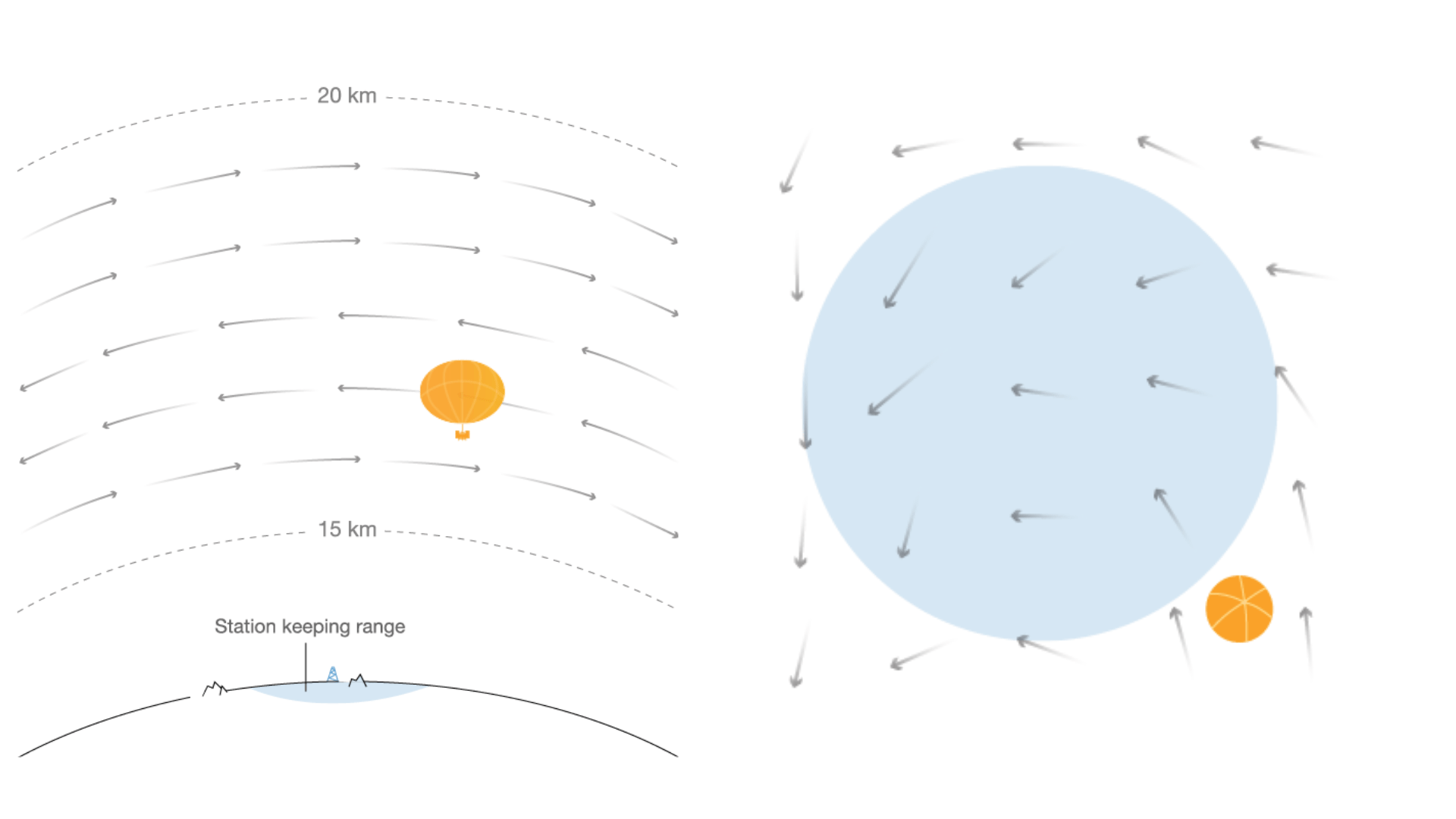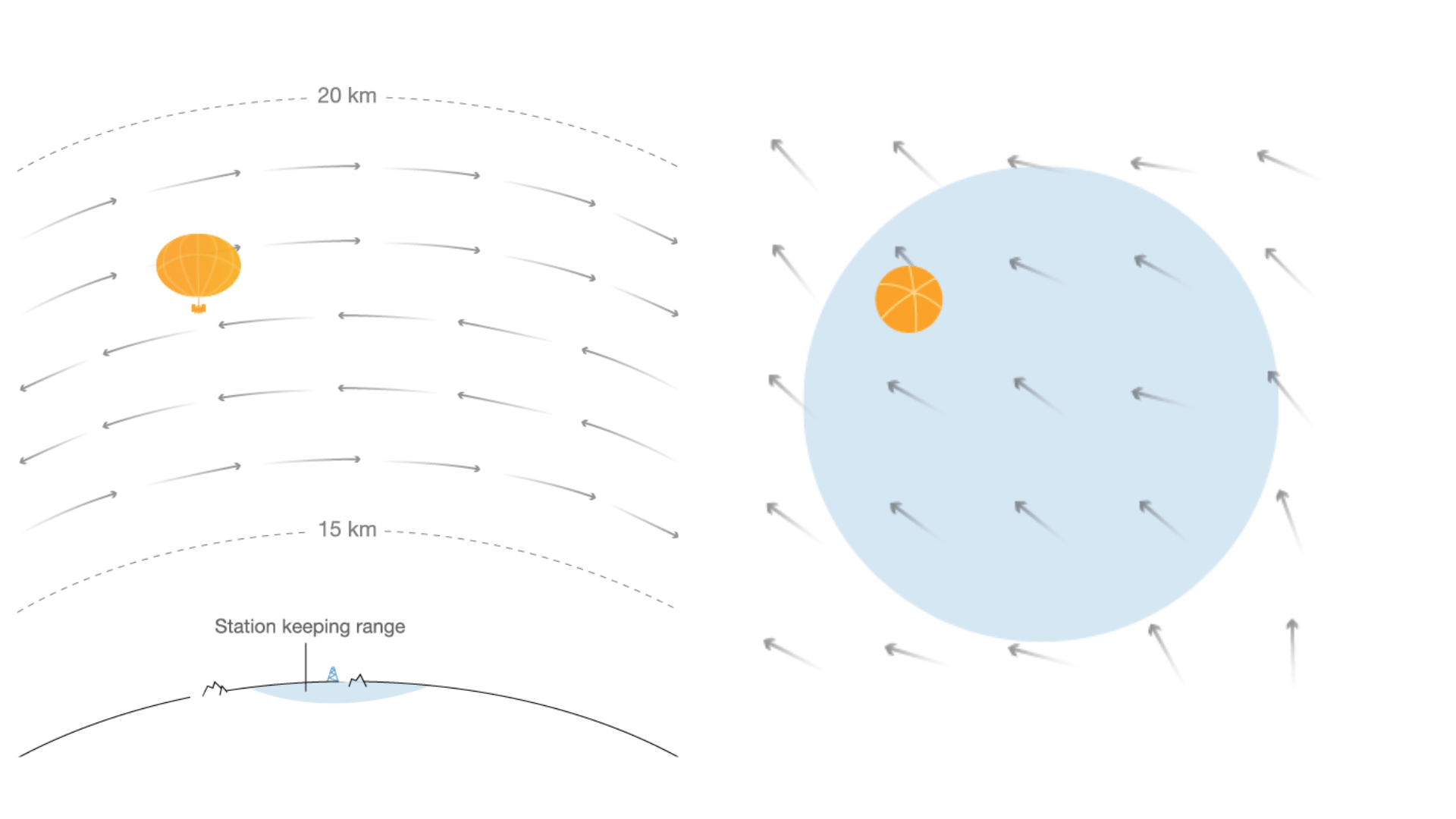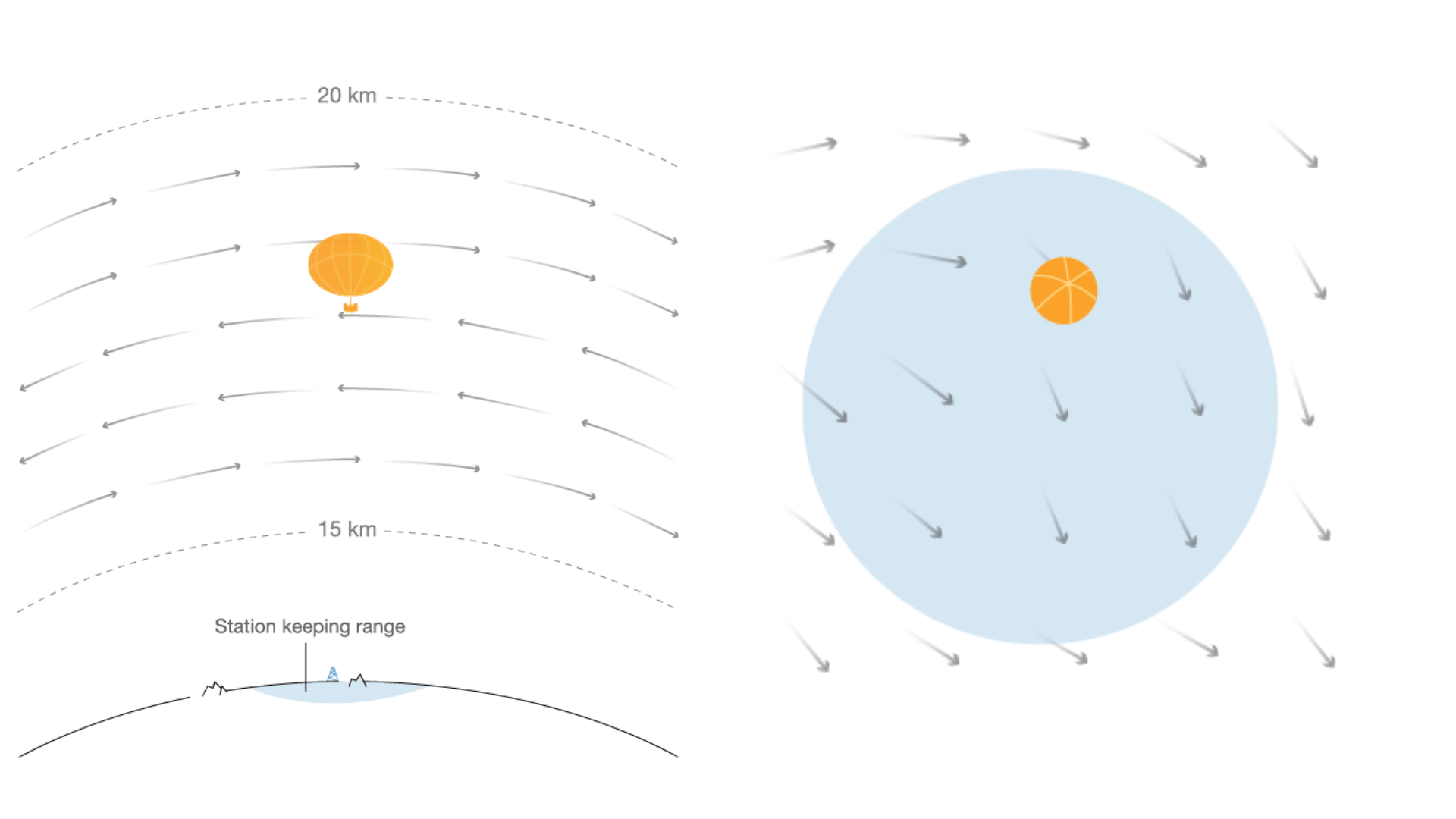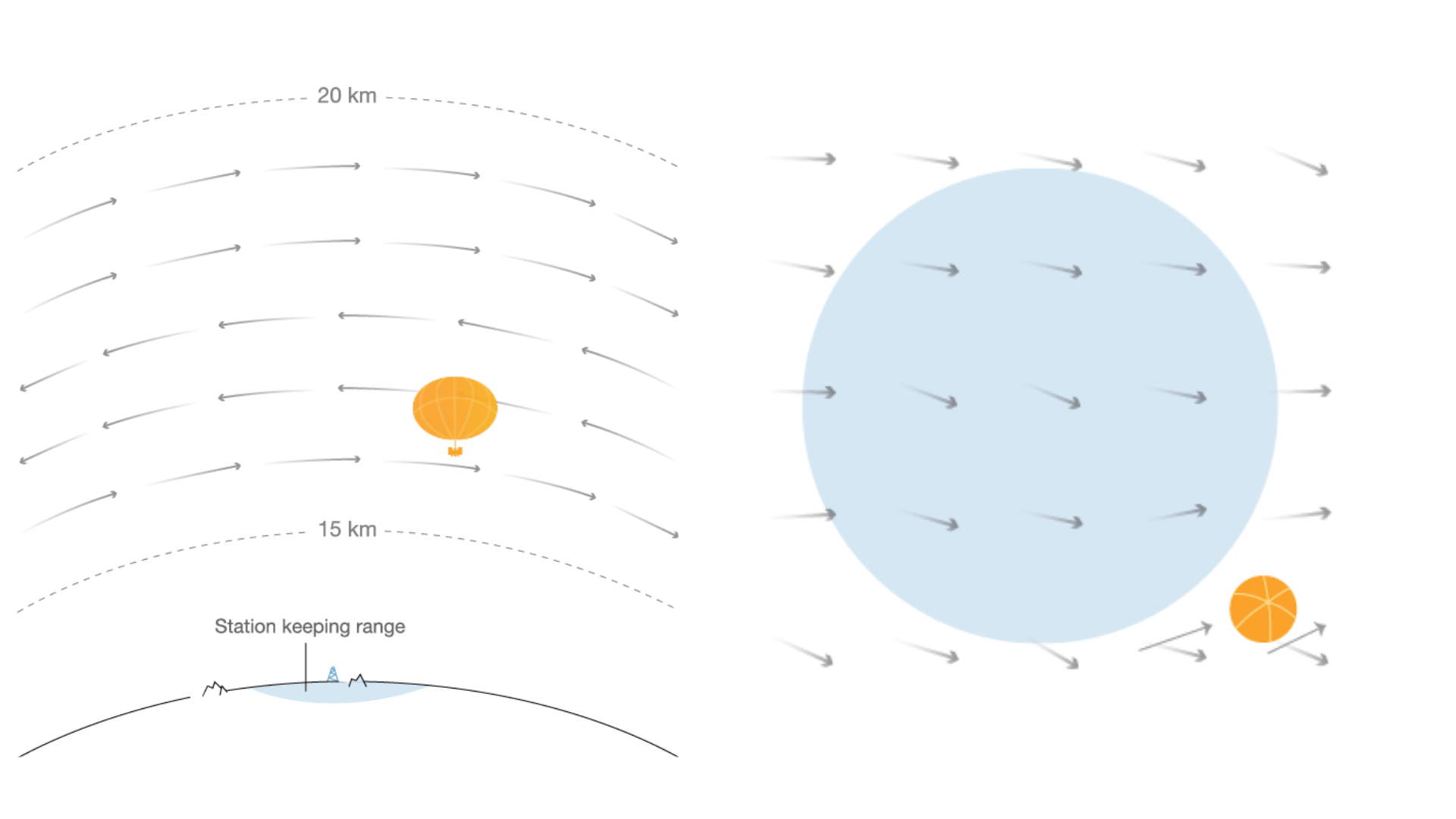
Autonomous navigation of stratospheric balloons using reinforcement learning
Marc G. Bellemare, Salvatore Candido, Pablo Samuel Castro, Jun Gong, Marlos C. Machado, Subhodeep Moitra, Sameera S. Ponda and Ziyu Wang
In this work we, quite literally, take reinforcement learning to new heights! Specifically, we use deep reinforcement learning to help control the navigation of stratospheric balloons, whose purpose is to deliver internet to areas with low connectivity. This project is an ongoing collaboration with Loon.
You can find links to more details in my blog post.
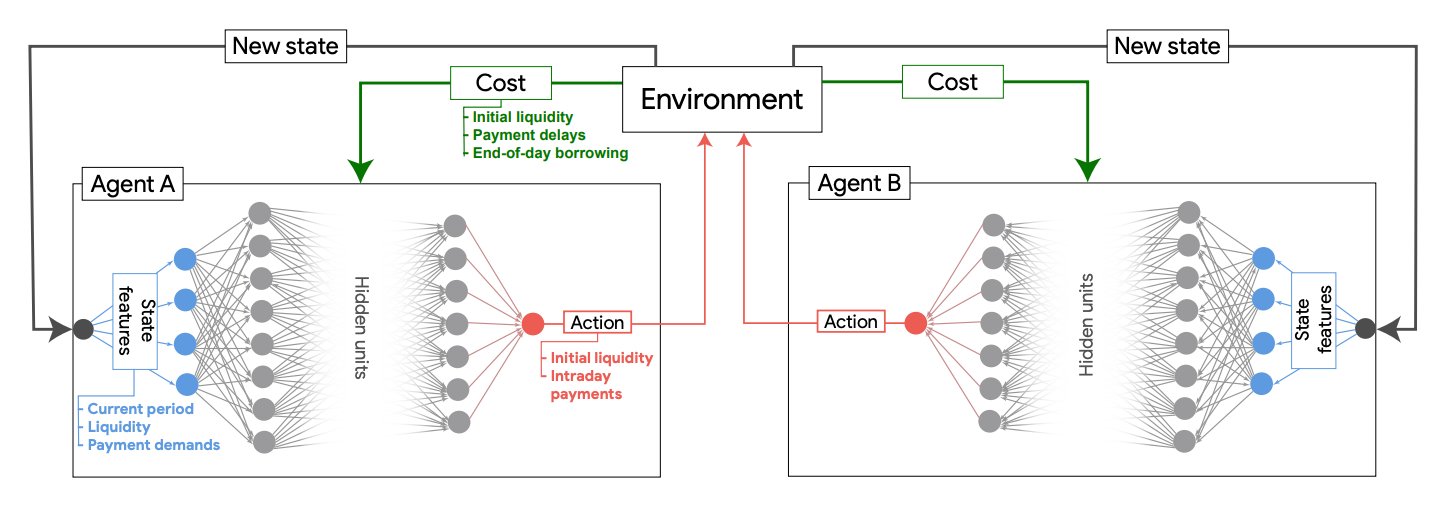
Estimating Policy Functions in Payment Systems using Reinforcement Learning
Pablo Samuel Castro, Ajit Desai, Han Du, Rodney Garratt, Francisco Rivadeneyra
This is another exception to the first rule. It was presented at the latest NeurIPS ML for Economic Policy workshop, and was awarded best empirical paper.
This paper is the result of an ongoing collaboration I have with the Bank of Canada. In this work we are demonstrating that RL can be a useful tool in simulating, evaluating, and ultimately understanding the complex dynamics of inter-bank high-value payment systems.
Agence: a dynamic film exploring multi-agent systems and human agency
_Dante Camarena†, Pietro Gagliano, Alexander Bakogeorge, Nicholas Counter, Anuj Patel, Casey Blustein, Erin Ray, David Oppenheim, Laura Mingail, Kory W. Matthewson, Pablo Samuel Castro_Yet another exception to my first rule, but I like this work because it is showing how you can use RL (and ML in general) in a creative manner and deploy it to users around the world. This was showcased at the Venice VR film festival this year, and was accepted as an oral at the NeurIPS Machine Learning for Creativity & Design workshop. I also have a small blog post about it.
Agence is a dynamic and interactive film authored by three parties: 1) the director, who establishes the narrative structure and environment, 2) intelligent agents, using reinforcement learning or scripted (hierarchical state machines) AI, and 3) the viewer, who can interact with the system to affect the simulation. We trained RL agents in a multi-agent fashion to control some (or all, based on user choice) of the agents in the film.
The following video does a great job at explaining more what it’s about.
The Story Behind Agence - A Dynamic Film from Transitional Forms on Vimeo.
Other
Finally, I’m including a couple of papers that I thought were proposing something which, to me, seems quite innovative.
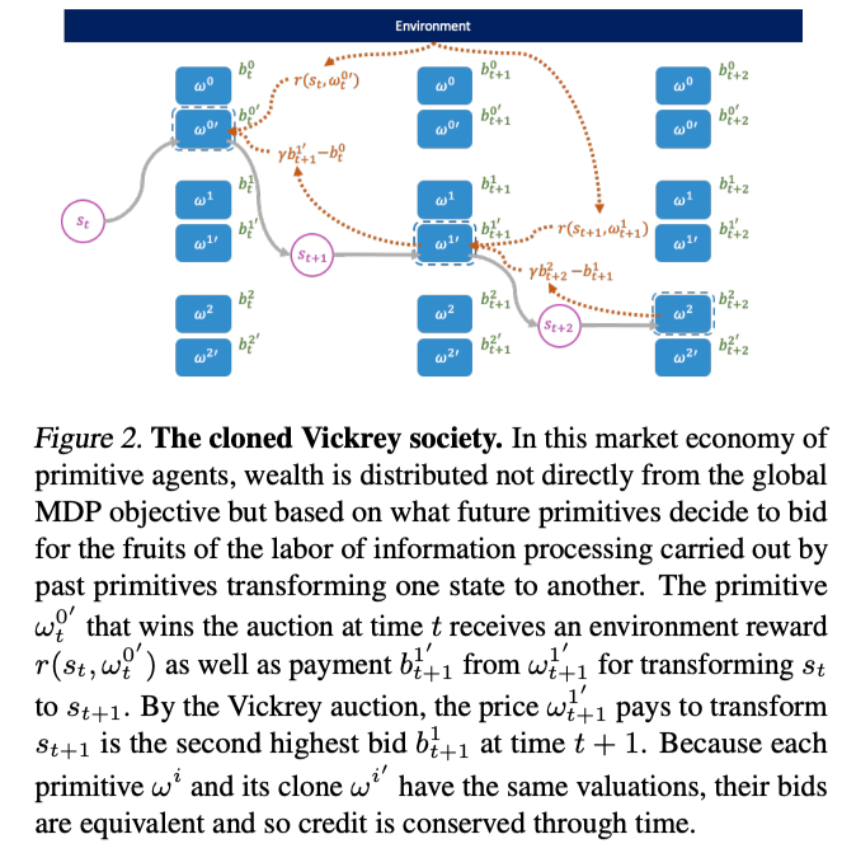
Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions
Michael Chang, Sid Kaushik, S. Matthew Weinberg, Tom Griffiths, Sergey Levine
We design a mechanism for defining the learning environment of each agent for which we know that the optimal solution for the global objective coincides with a Nash equilibrium strategy profile of the agents optimizing their own local objectives. The society functions as an economy of agents that learn the credit assignment process itself by buying and selling to each other the right to operate on the environment state. We derive a class of decentralized reinforcement learning algorithms that are broadly applicable not only to standard reinforcement learning but also for selecting options in semi-MDPs and dynamically composing computation graphs.
Munchausen Reinforcement Learning
Nino Vieillard, Olivier Pietquin, Matthieu Geist
Our core contribution stands in a very simple idea: adding the scaled log-policy to the immediate reward. We show that slightly modifying Deep Q-Network (DQN) in that way provides an agent that is competitive with distributional methods on Atari games, without making use of distributional RL, n-step returns or prioritized replay. To demonstrate the versatility of this idea, we also use it together with an Implicit Quantile Network (IQN). The resulting agent outperforms Rainbow on Atari, installing a new State of the Art with very little modifications to the original algorithm.

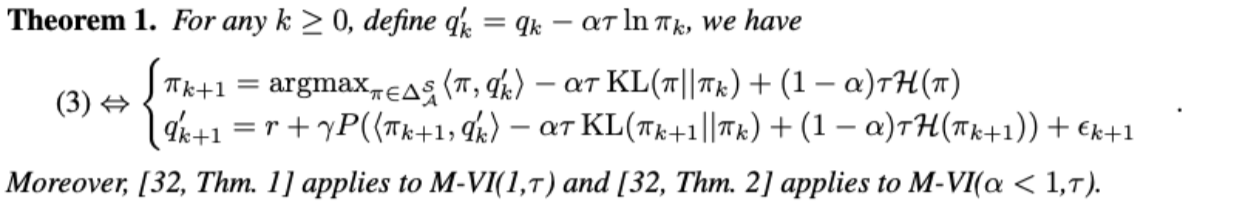
An operator view of policy gradient methods
Dibya Ghosh, Marlos C. Machado, Nicolas Le Roux
We cast policy gradient methods as the repeated application of two operators: a policy improvement operator $\mathcal{I}$, which maps any policy $\pi$ to a better one $\mathcal{I}\pi$, and a projection operator $\mathcal{P}$, which finds the best approximation of $\mathcal{I}\pi$ in the set of realizable policies. We use this framework to introduce operator-based versions of well-known policy gradient methods such as REINFORCE and PPO, which leads to a better understanding of their original counterparts. We also use the understanding we develop of the role of $\mathcal{I}$ and $\mathcal{P}$ to propose a new global lower bound of the expected return. This new perspective allows us to further bridge the gap between policy-based and value-based methods, showing how REINFORCE and the Bellman optimality operator, for example, can be seen as two sides of the same coin.
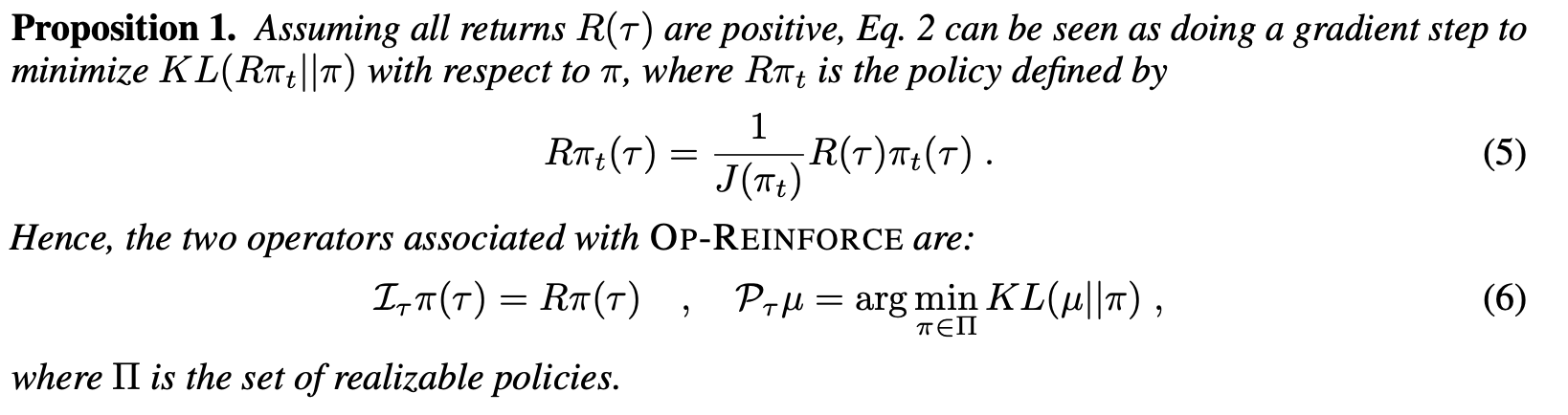

What Can Learned Intrinsic Rewards Capture?
Zeyu Zheng, Junhyuk Oh, Matteo Hessel, Zhongwen Xu, Manuel Kroiss, Hado van Hasselt, David Silver, Satinder Singh
We propose a scalable meta-gradient framework for learning useful intrinsic reward functions across multiple lifetimes of experience. Through several proof-of-concept experiments, we show that it is feasible to learn and capture knowledge about long-term exploration and exploitation into a reward function.

comments powered by Disqus