
In Defense of Atari - the ALE is not 'solved'!
This post is based on a talk I gave at the AutoRL workshop in ICML 2024, which unfortunately was not recorded.
Introduction
Reinforcement Learning (RL) has been used successfully in a number of challenging tasks, such as beating world champions at Go, controlling tokamak plasmas for nuclear fusion, optimized chip placement, and controlling stratospheric balloons. All these successes have leveraged years of research and expertise and, importantly, rely on the combination of RL algorithms with deep neural networks (as proposed in the seminal DQN paper).

From "Bigger, Better, Faster" to "Smaller, Sparser, Stranger"
This is a post based on a talk I gave a few times in 2023. I had been meaning to put it in blog post form for over a year but kept putting it off… I guess better late than never. I think some of the ideas still hold, so hope some of you find it useful!
Bigger, better, faster
In the seminal DQN paper, Mnih et al. demonstrated that reinforcement learning, when combined with neural networks as function approximators, could learn to play Atari 2600 games at superhuman levels. The DQN agent learned to do this over 200 million environment frames, which is roughly equivalent to 1000 hours of human gameplay…
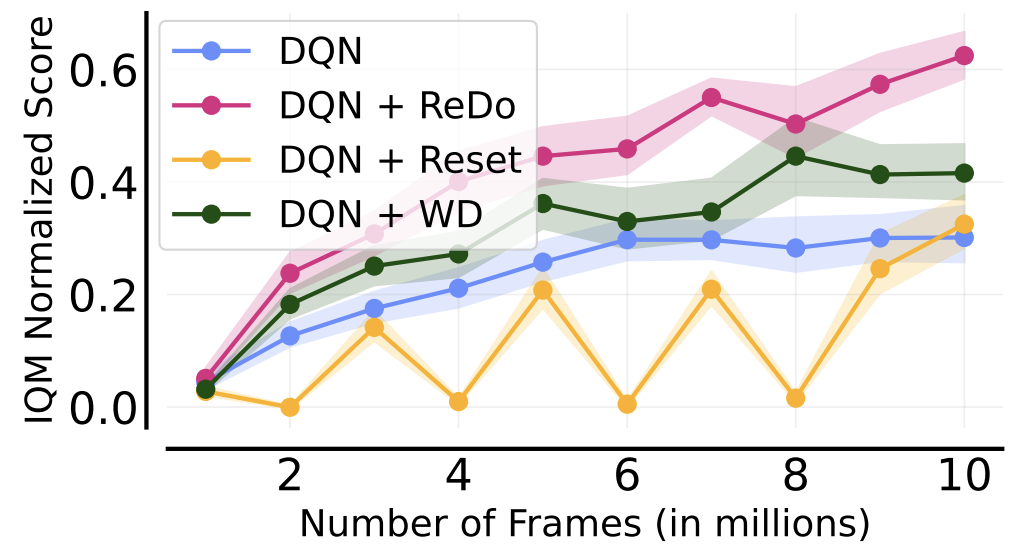
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
We identify the dormant neuron phenomenon in deep reinforcement learning, where an agent’s network suffers from an increasing number of inactive neurons, thereby affecting network expressivity.
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro*, Utku Evci*
This blogpost is a summary of our ICML 2023 paper. The code is available here. Many more results and analyses are available in the paper, so I encouraged you to check it out if interested!
The following figure gives a nice summary of the overall findings of our work (we are reporting the Interquantile Mean (IQM) as introduced in our Statistical Precipice NeurIPS'21 paper):

Th State of Spars Train ng in D ep Re nforc m nt Le rn ng
We perform a systematic investigation into applying a number of existing sparse training techniques on a variety of deep RL agents and environments, and conclude by suggesting promising avenues for improving the effectiveness of sparse training methods, as well as for advancing their use in DRL.
Laura Graesser*, Utku Evci*, Erich Elsen, Pablo Samuel Castro
This blogpost is a summary of our ICML 2022 paper. The code is available here. Many more results and analyses are available in the paper, so I encouraged you to check it out if interested!
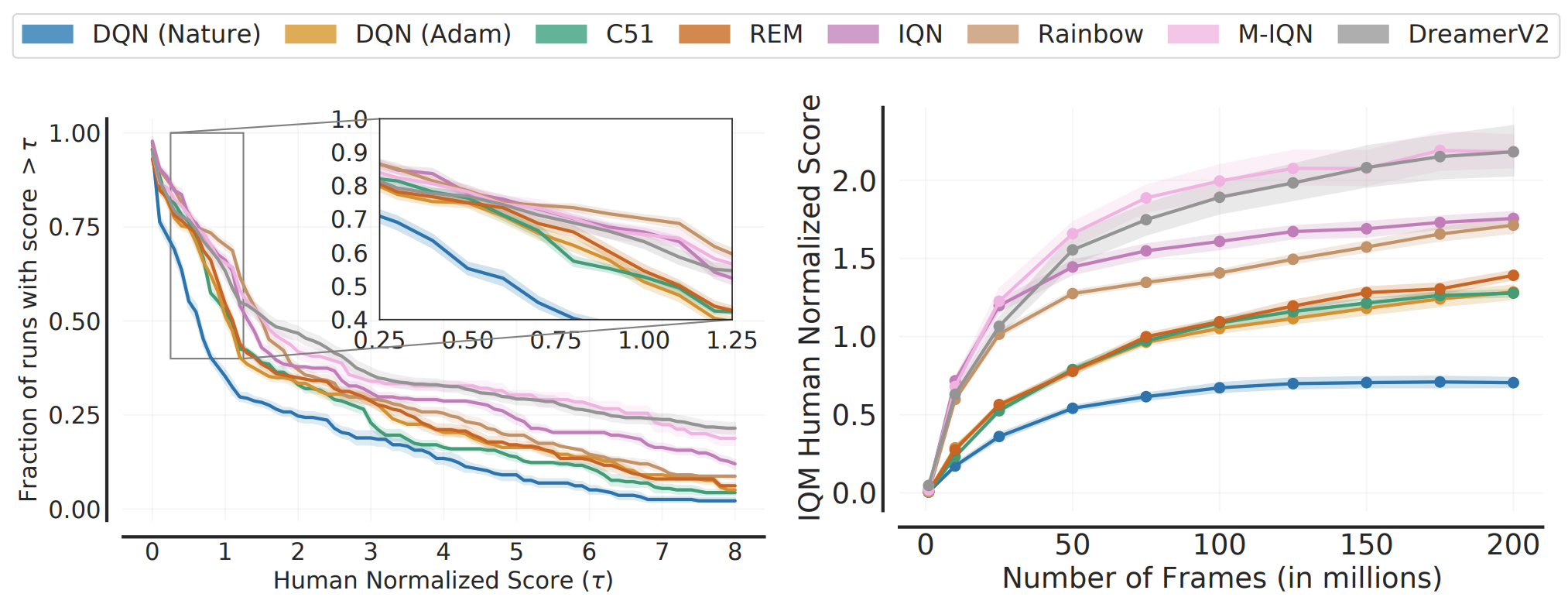
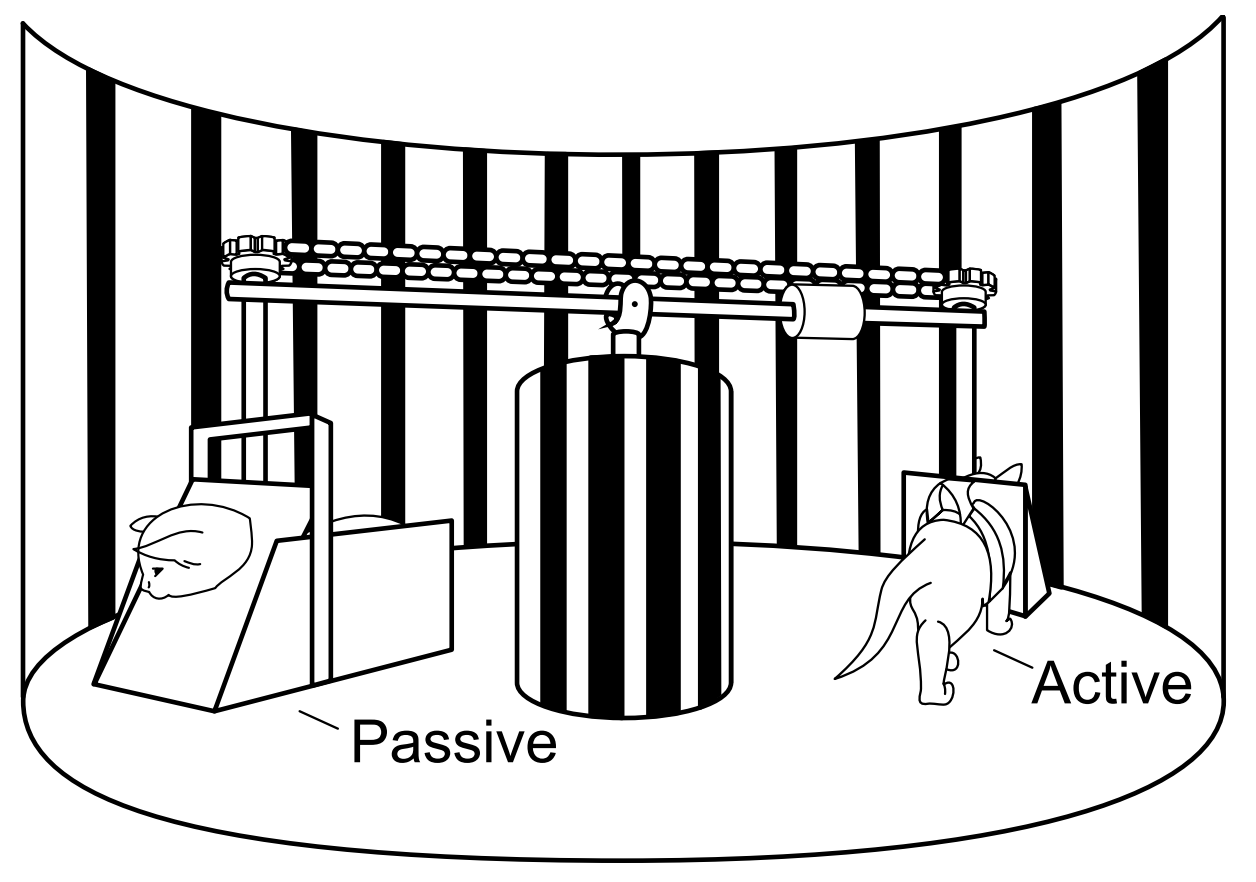
The Difficulty of Passive Learning in Deep Reinforcement Learning
We propose the “tandem learning” experimental design, where two RL agents are learning from identical data streams, but only one interacts with the environment to collect the data. We use this experiment design to study the empirical challenges of offline reinforcement learning.
Georg Ostrovski, Pablo Samuel Castro, Will Dabney
This blogpost is a summary of our NeurIPS 2021 paper. We provide two Tandem RL implementations: this one based on the DQN Zoo, and this one based on the Dopamine library.

MICo: Learning improved representations via sampling-based state similarity for Markov decision processes
We present a new behavioural distance over the state space of a Markov decision process, and demonstrate the use of this distance as an effective means of shaping the learnt representations of deep reinforcement learning agents.
Pablo Samuel Castro*, Tyler Kastner*, Prakash Panangaden, and Mark Rowland
This blogpost is a summary of our NeurIPS 2021 paper. The code is available here.
The following figure gives a nice summary of the empirical gains our new loss provides, yielding an improvement on all of the Dopamine agents (left), as well as over Soft Actor-Critic and the DBC algorithm of Zhang et al., ICLR 2021 (right). In both cases we are reporting the Interquantile Mean as introduced in our Statistical Precipice NeurIPS'21 paper.
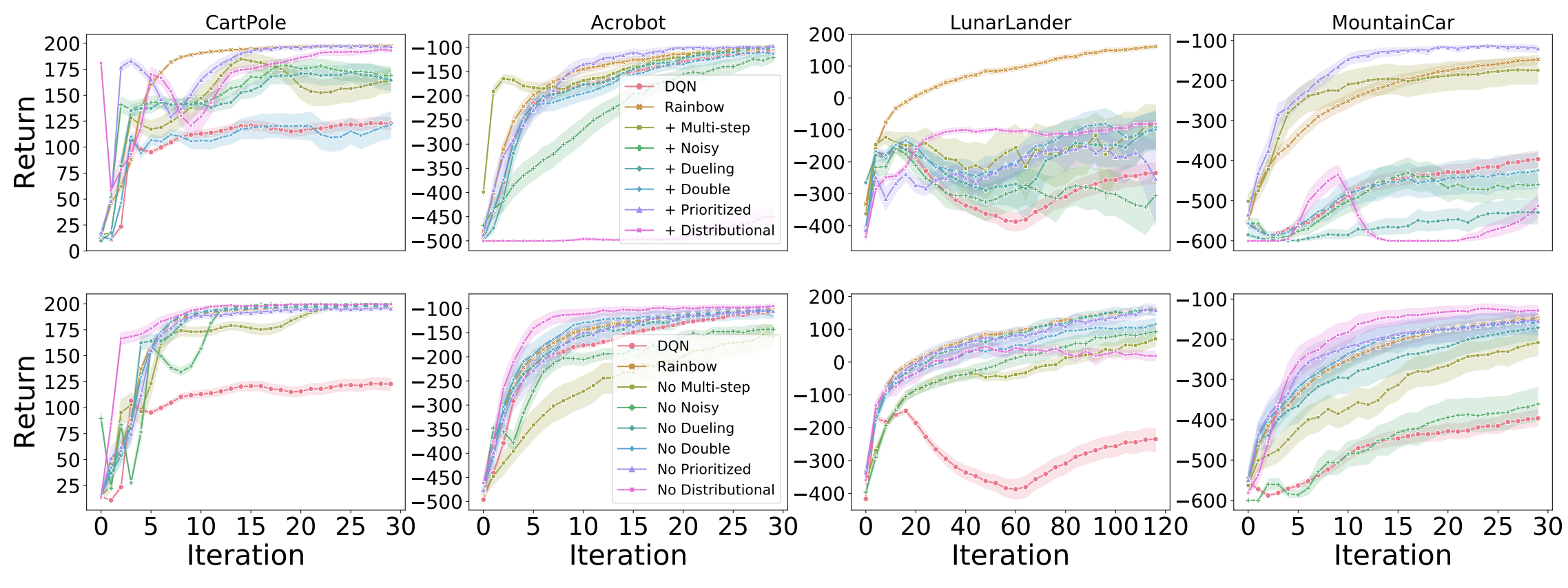
Revisiting Rainbow: Promoting more insightful and inclusive deep reinforcement learning research
We argue for the value of small- to mid-scale environments in deep RL for increasing scientific insight and help make our community more inclusive.
Johan S. Obando-Ceron and Pablo Samuel Castro
This is a summary of our paper which was accepted at the Thirty-eighth International Conference on Machine Learning (ICML'21). (An initial version was presented at the deep reinforcement learning workshop at NeurIPS 2020).
The code is available here.
You can see the Deep RL talk here.
Metrics and continuity in reinforcement learning
In this work we investigate the notion of “state similarity” in Markov decision processes. This concept is central to generalization in RL with function approximation.
Our paper was published at AAAI'21.
Charline Le Lan, Marc G. Bellemare, and Pablo Samuel Castro
The text below was adapted from Charline’s twitter thread
In RL, we often deal with systems with large state spaces. We can’t exactly represent the value of each of these states and need some type of generalization. One way to do that is to look at structured representations in which similar states are assigned similar predictions.
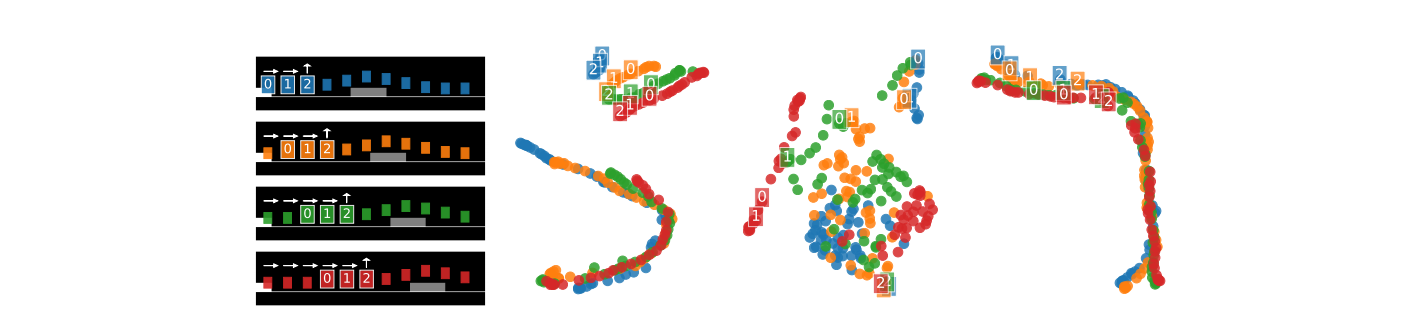
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
This paper was accepted as a spotlight at ICLR'21.
We propose a new metric and contrastive loss that comes equipped with theoretical and empirical results.

Policy Similarity Metric
We introduce the policy similarity metric (PSM) which is based on bisimulation metrics. In contrast to bisimulation metrics (which is built on reward differences), PSMs are built on differences in optimal policies.
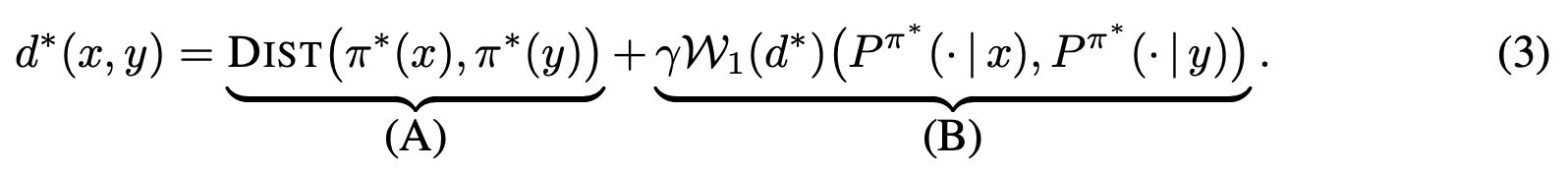
If we were to use this metric for policy transfer (as Doina Precup & I explored previously), we can upper-bound the difference between the optimal and the transferred policy:
2020 RL highlights
As part of TWiML ’s AI Rewind series, I was asked to provide a list of reinforcement learning papers that were highlights for me in 2020. It’s been a difficult year for pretty much everyone, but it’s heartening to see that despite all the difficulties, interesting research still came out.
Given the size and breadth of the reinforcement learning research, as well as the fact that I was asked to do this at the end of NeurIPS and right before my vacation, I decided to apply the following rules in the selection:
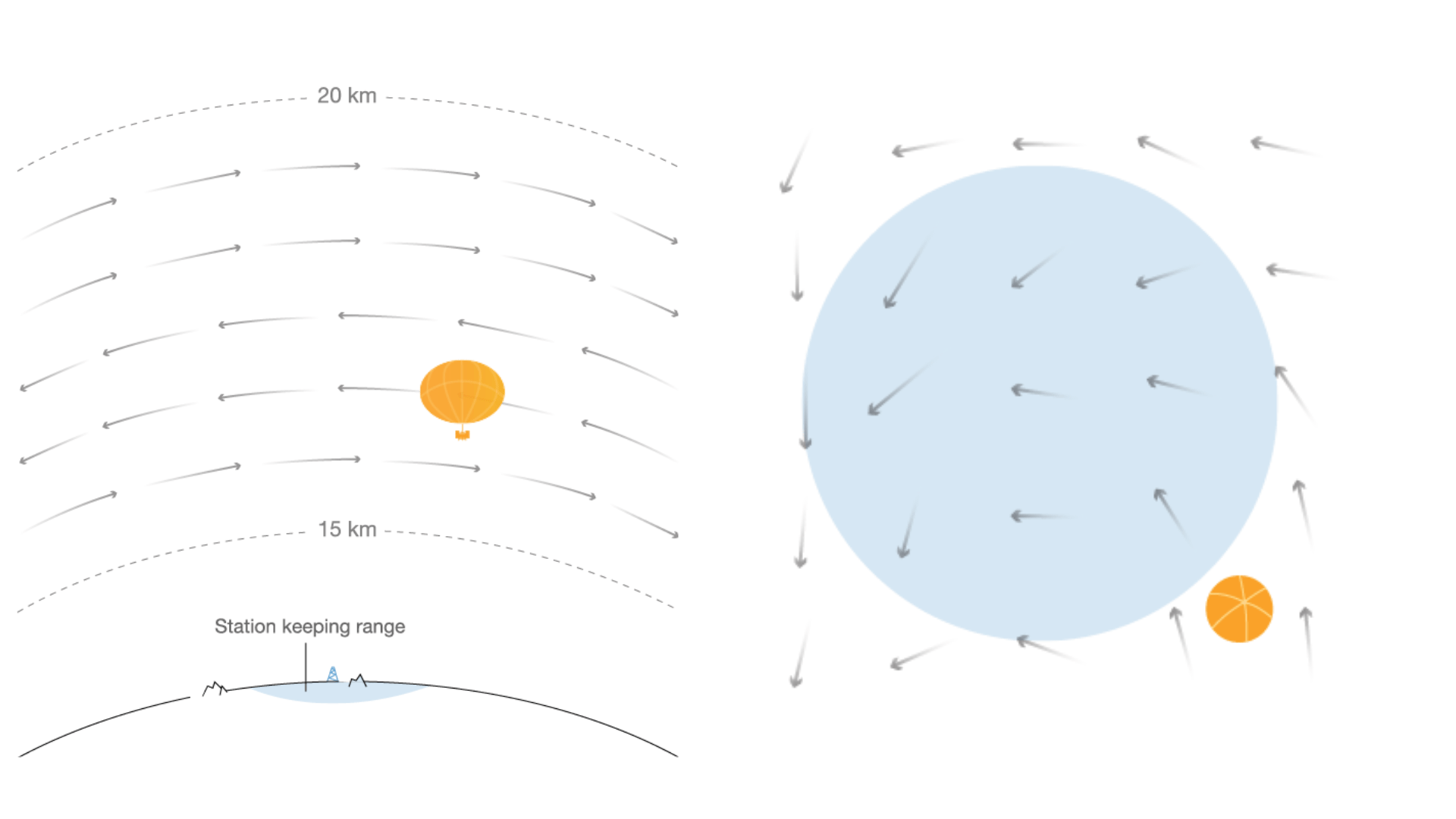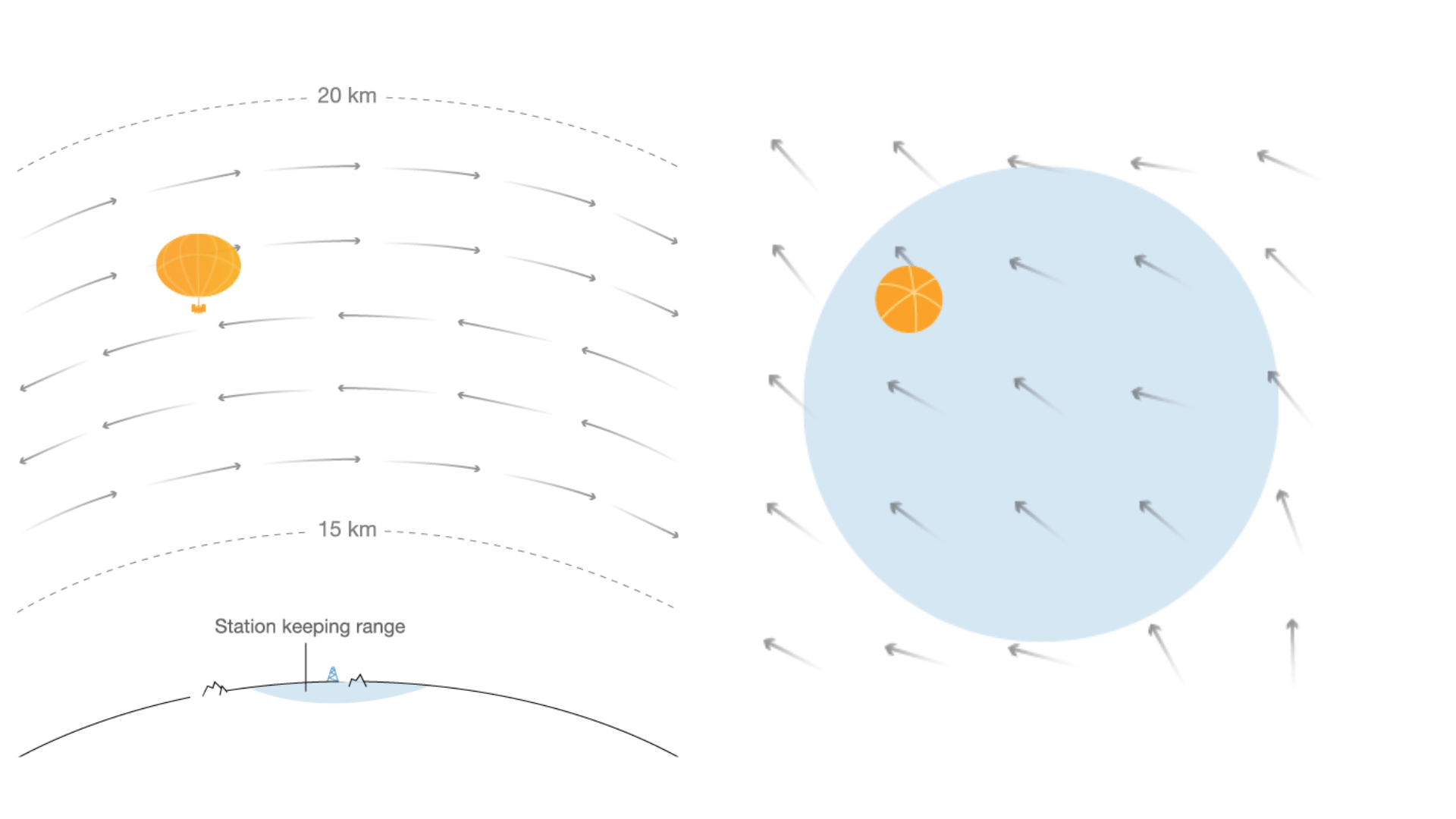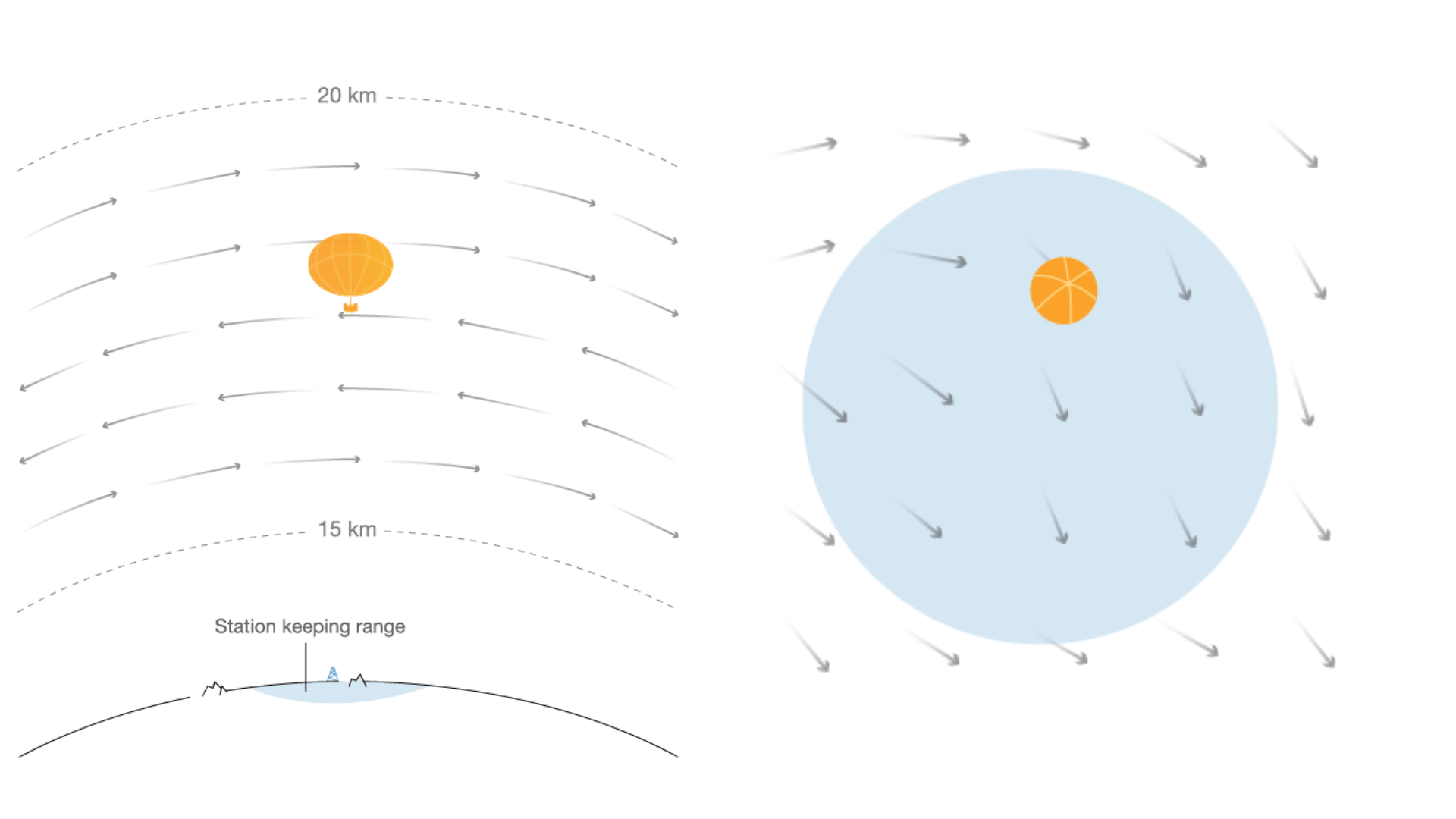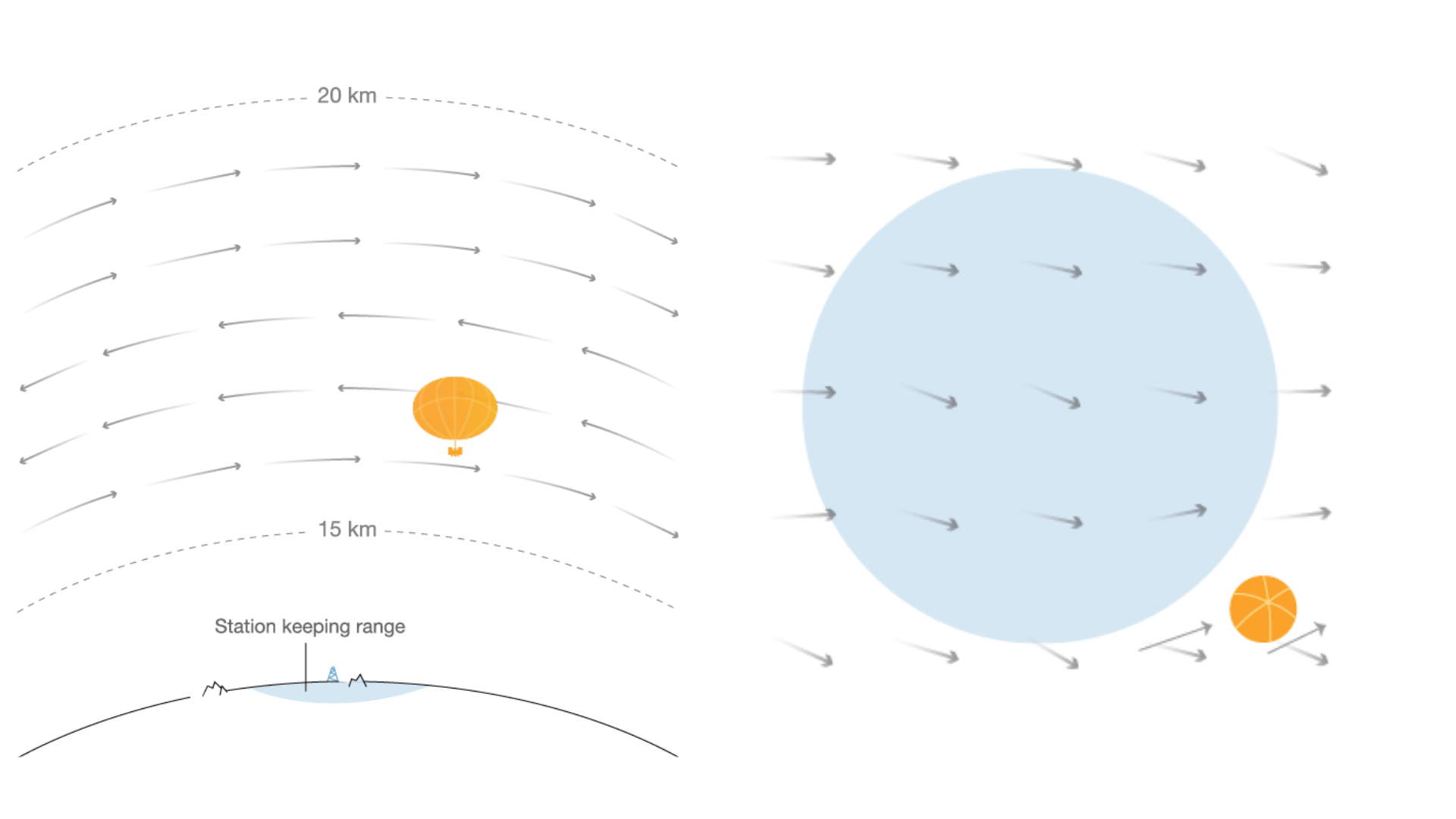
Autonomous navigation of stratospheric balloons using reinforcement learning
In this work we, quite literally, take reinforcement learning to new heights! Specifically, we use deep reinforcement learning to help control the navigation of stratospheric balloons, whose purpose is to deliver internet to areas with low connectivity. This project is an ongoing collaboration with Loon.
It’s been incredibly rewarding to see reinforcement learning deployed successfully in a real setting. It’s also been terrific to work alongside such fantastic co-authors:
Marc G. Bellemare, Salvatore Candido, Pablo Samuel Castro, Jun Gong, Marlos C. Machado, Subhodeep Moitra, Sameera S. Ponda, Ziyu Wang