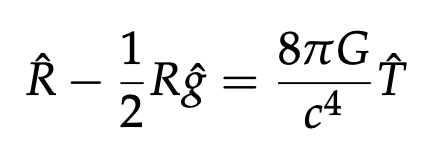
Metrics and continuity in reinforcement learning
In this work we investigate the notion of “state similarity” in Markov decision processes. This concept is central to generalization in RL with function approximation.
Our paper was published at AAAI'21.
Charline Le Lan, Marc G. Bellemare, and Pablo Samuel Castro
The text below was adapted from Charline’s twitter thread
In RL, we often deal with systems with large state spaces. We can’t exactly represent the value of each of these states and need some type of generalization. One way to do that is to look at structured representations in which similar states are assigned similar predictions.

Episode 1: Musical Notes & Computation
The code for this episode is available here.
I originally thought this channel would be a kind of educational channel, where people could learn about both music and computer science in a fun and informal way. I tweeted asking for suggestions for what to cover first on the CS side, and Kory Mathewson’s response was my favourite.
On the music side, it was kind of a train-of-thought process. The first thing that came to mind when thinking about the first thing you might learn in music theory was musical notes themselves.

Introducing MUSICODE
A musical ode to musical code.
Subscribe to the YouTube channel!.
Each episode will explore a topic in Computer Science, a topic in Music, and combine them in creative ways.
You can find the code I use for each episode here!
The story
The reason I decided to start this show was because, thanks to COVID-19, I was no longer performing live with my jazz trio, but I was aching for some type of performative output. I had recently bought a disklavier, which had been a dream of mine for quite some time, especially after seeing Dan Tepfer’s Natural Machines.
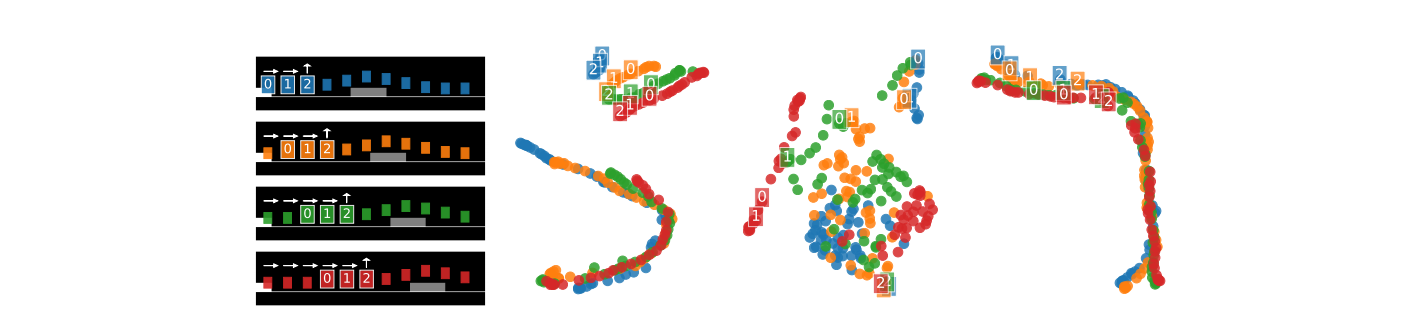
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
This paper was accepted as a spotlight at ICLR'21.
We propose a new metric and contrastive loss that comes equipped with theoretical and empirical results.

Policy Similarity Metric
We introduce the policy similarity metric (PSM) which is based on bisimulation metrics. In contrast to bisimulation metrics (which is built on reward differences), PSMs are built on differences in optimal policies.
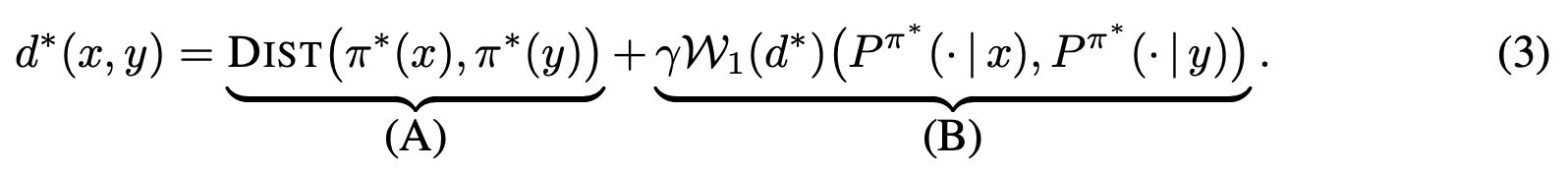
If we were to use this metric for policy transfer (as Doina Precup & I explored previously), we can upper-bound the difference between the optimal and the transferred policy:
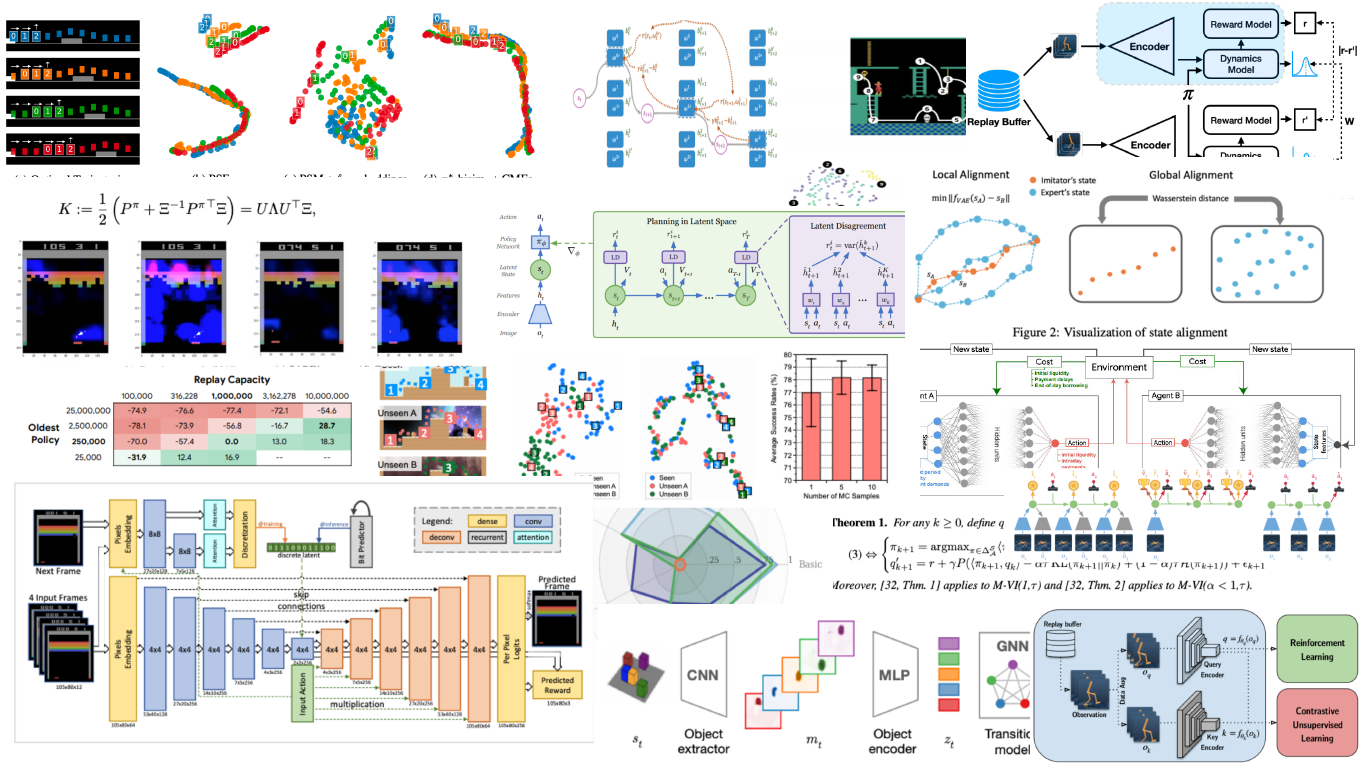
2020 RL highlights
As part of TWiML ’s AI Rewind series, I was asked to provide a list of reinforcement learning papers that were highlights for me in 2020. It’s been a difficult year for pretty much everyone, but it’s heartening to see that despite all the difficulties, interesting research still came out.
Given the size and breadth of the reinforcement learning research, as well as the fact that I was asked to do this at the end of NeurIPS and right before my vacation, I decided to apply the following rules in the selection:
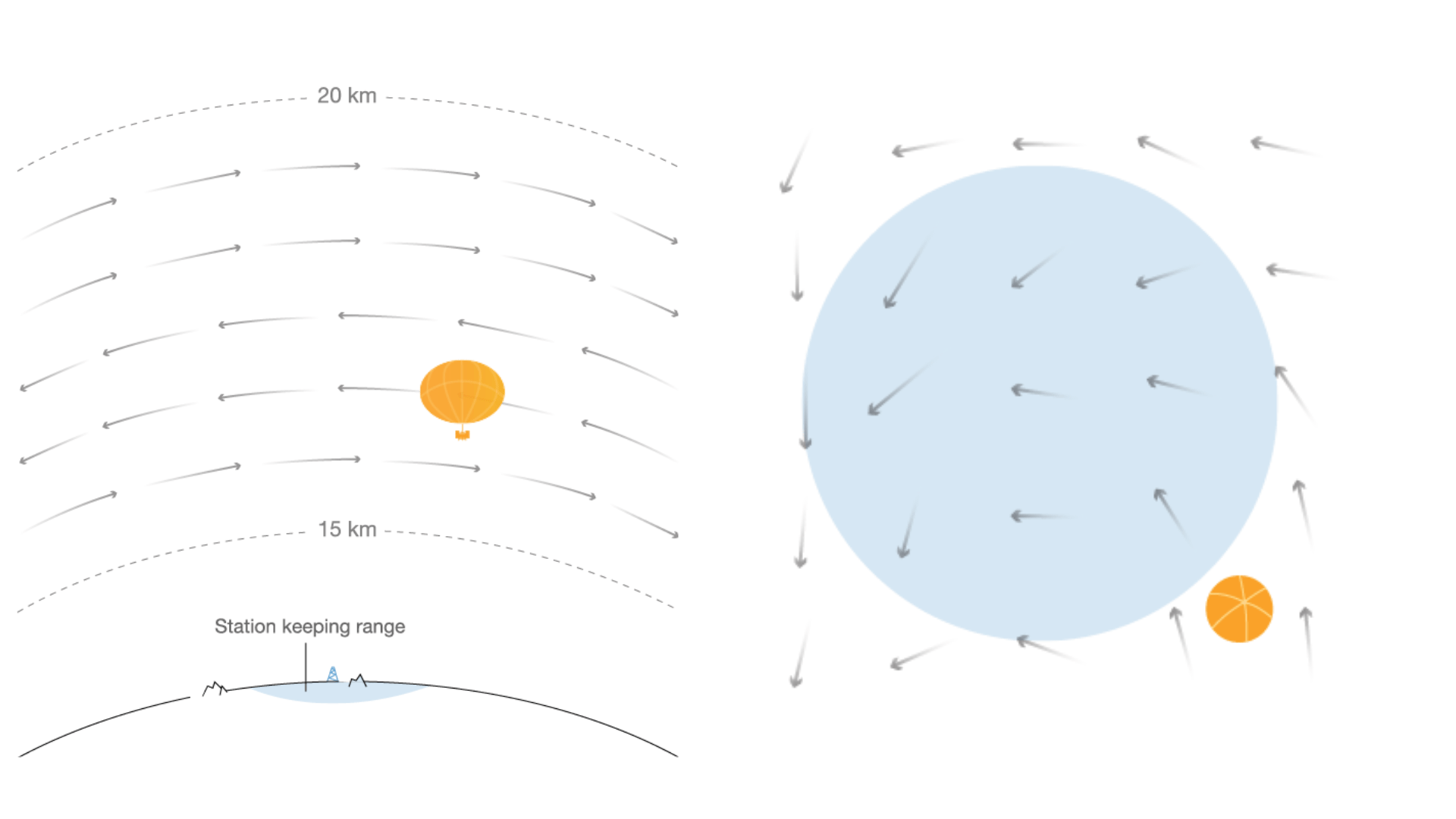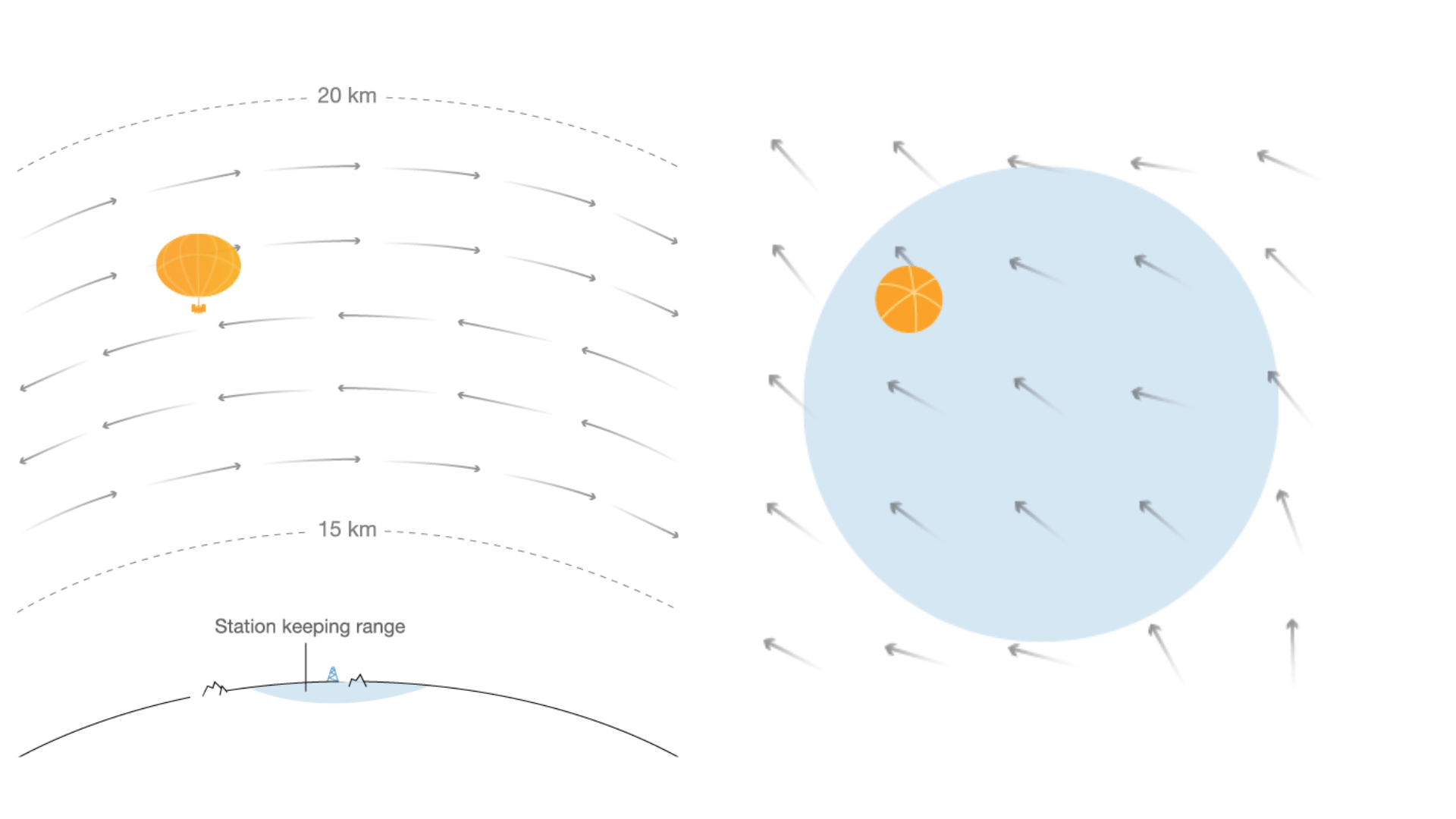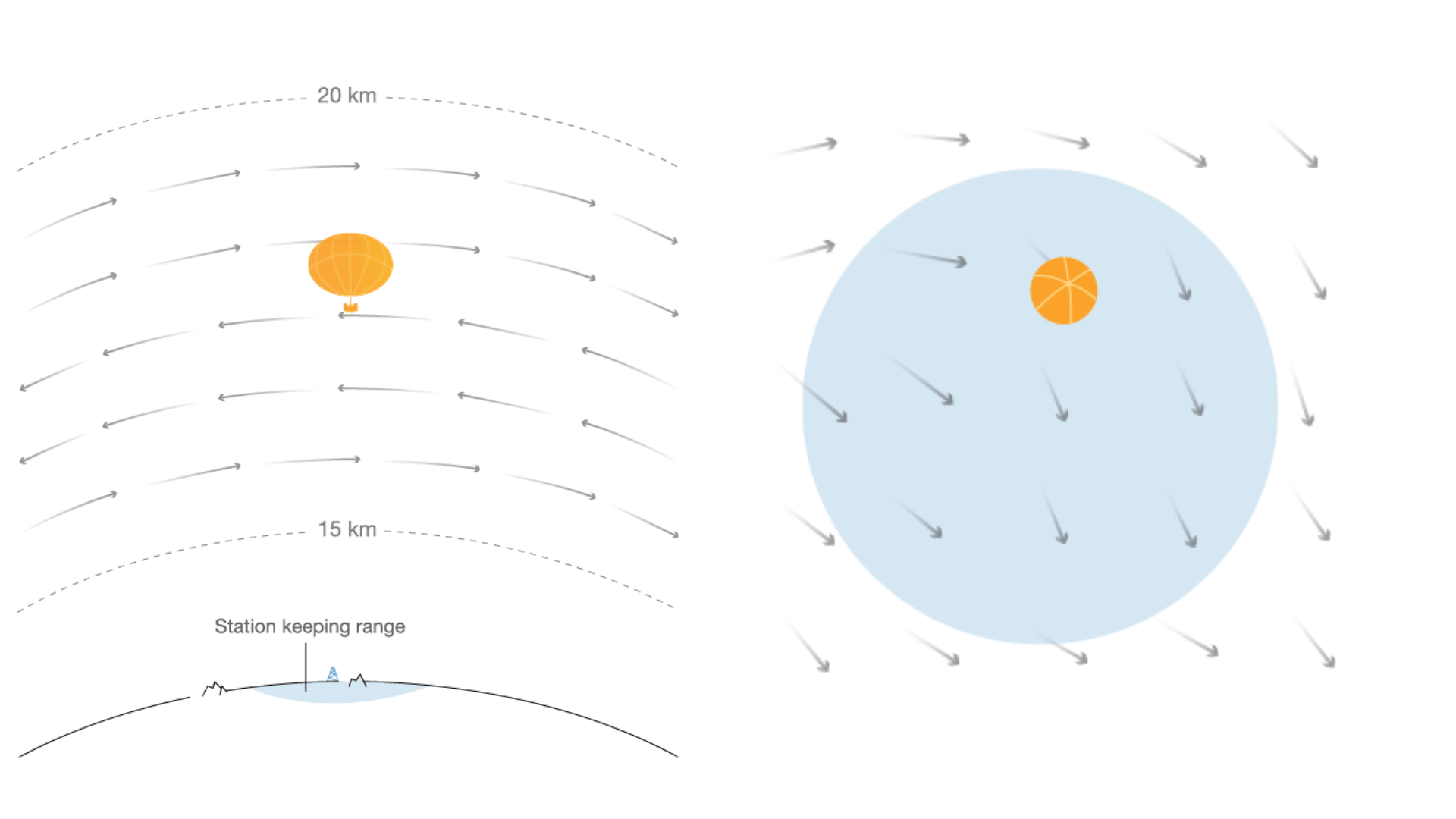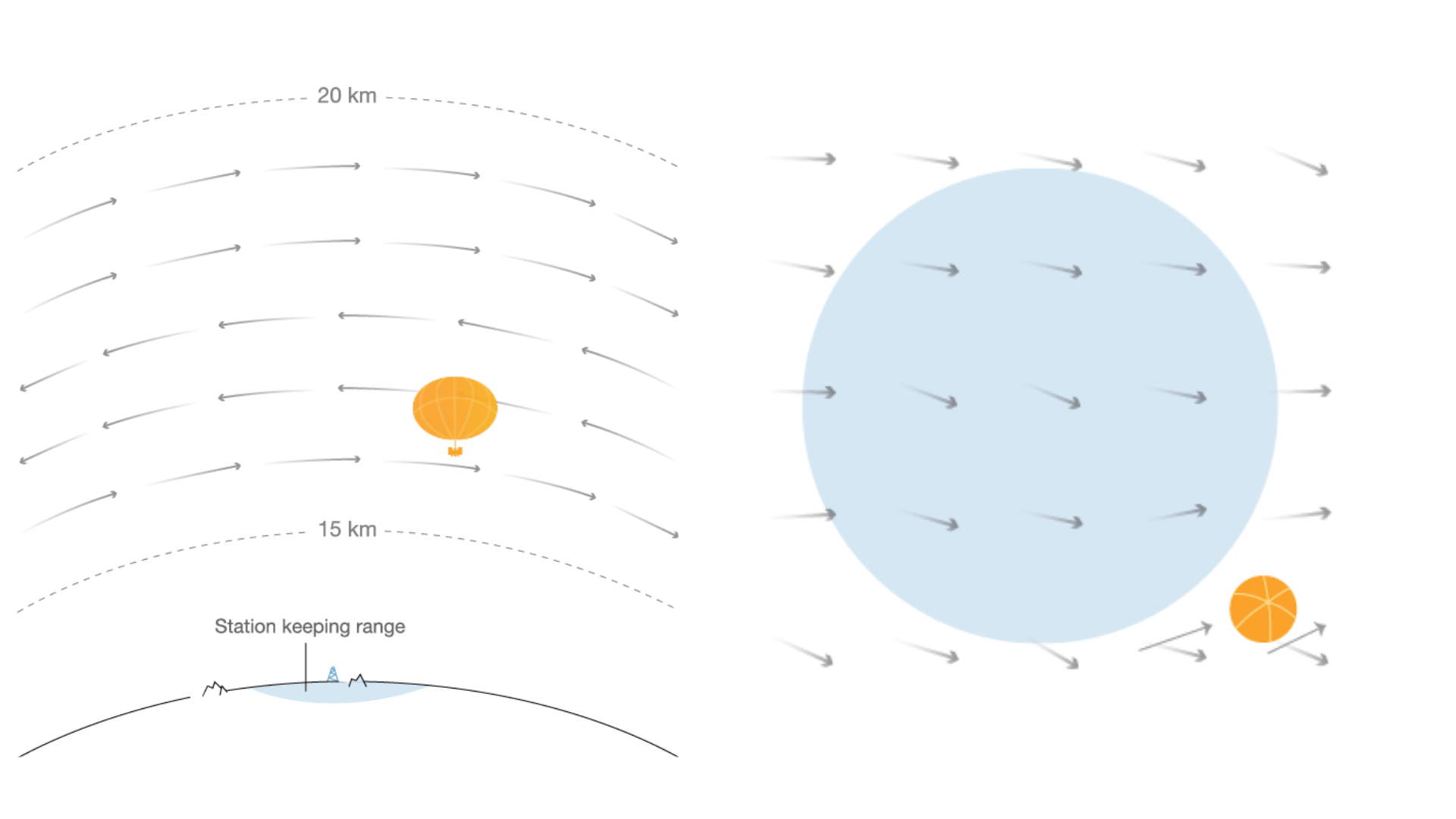
Autonomous navigation of stratospheric balloons using reinforcement learning
In this work we, quite literally, take reinforcement learning to new heights! Specifically, we use deep reinforcement learning to help control the navigation of stratospheric balloons, whose purpose is to deliver internet to areas with low connectivity. This project is an ongoing collaboration with Loon.
It’s been incredibly rewarding to see reinforcement learning deployed successfully in a real setting. It’s also been terrific to work alongside such fantastic co-authors:
Marc G. Bellemare, Salvatore Candido, Pablo Samuel Castro, Jun Gong, Marlos C. Machado, Subhodeep Moitra, Sameera S. Ponda, Ziyu Wang

Agence: a dynamic film exploring multi-agent systems and human agency
Agence is a dynamic and interactive film authored by three parties: 1) the director, who establishes the narrative structure and environment, 2) intelligent agents, using reinforcement learning or scripted (hierarchical state machines) AI, and 3) the viewer, who can interact with the system to affect the simulation. We trained RL agents in a multi-agent fashion to control some (or all, based on user choice) of the agents in the film. You can download the game at the Agence website.

GANterpretations
GANterpretations is an idea I published in this paper, which was accepted to the 4th Workshop on Machine Learning for Creativity and Design at NeurIPS 2020. The code is available here.
At a high level what it does is use the spectrogram of a piece of audio (from a video, for example) to “draw” a path in the latent space of a BigGAN.
The following video walks through the process:
GANs
GANs are generative models trained to reproduce images from a given dataset. The way GANs work is they are trained to learn a latent space $ Z\in\mathbb{R}^d $, where each point $ z\in Z $ generates a unique image $ G(z) $, where $ G $ is the generator of the GAN. When trained properly, these latent spaces are learned in a structured manner, where nearby points generate similar images.

Introduction to reinforcement learning
This post is based on this colab.
You can also watch a video where I go through the basics here.
Pueden ver un video (en español) donde presento el material aquí.
Introduction
Reinforcement learning methods are used for sequential decision making in uncertain environments. It is typically framed as an agent (the learner) interacting with an environment which provides the agent with reinforcement (positive or negative), based on the agent’s decisions. The agent leverages this reinforcement to update its behaviour in an aim to get closer to acting optimally. In interacting with the uncertain environment, the agent is also learning about the dynamics of the underlying system.

Rigging the Lottery: Making All Tickets Winners
Rigging the Lottery: Making All Tickets Winners is a paper published at ICML 2020 with Utku Evci, Trevor Gale, Jacob Menick, and Erich Elsen, where we introduce an algorithm for training sparse neural networks that uses a fixed parameter count and computational cost throughout training, without sacrificing accuracy relative to existing dense-to-sparse training methods.
You can read more about it in the paper and in our blog post.