In Defense of Atari - the ALE is not 'solved'!
This post is based on a talk I gave at the AutoRL workshop in ICML 2024, which unfortunately was not recorded.
Introduction
Reinforcement Learning (RL) has been used successfully in a number of challenging tasks, such as beating world champions at Go, controlling tokamak plasmas for nuclear fusion, optimized chip placement, and controlling stratospheric balloons. All these successes have leveraged years of research and expertise and, importantly, rely on the combination of RL algorithms with deep neural networks (as proposed in the seminal DQN paper).

From "Bigger, Better, Faster" to "Smaller, Sparser, Stranger"
This is a post based on a talk I gave a few times in 2023. I had been meaning to put it in blog post form for over a year but kept putting it off… I guess better late than never. I think some of the ideas still hold, so hope some of you find it useful!
Bigger, better, faster
In the seminal DQN paper, Mnih et al. demonstrated that reinforcement learning, when combined with neural networks as function approximators, could learn to play Atari 2600 games at superhuman levels. The DQN agent learned to do this over 200 million environment frames, which is roughly equivalent to 1000 hours of human gameplay…
The Dormant Neuron Phenomenon in Deep Reinforcement Learning
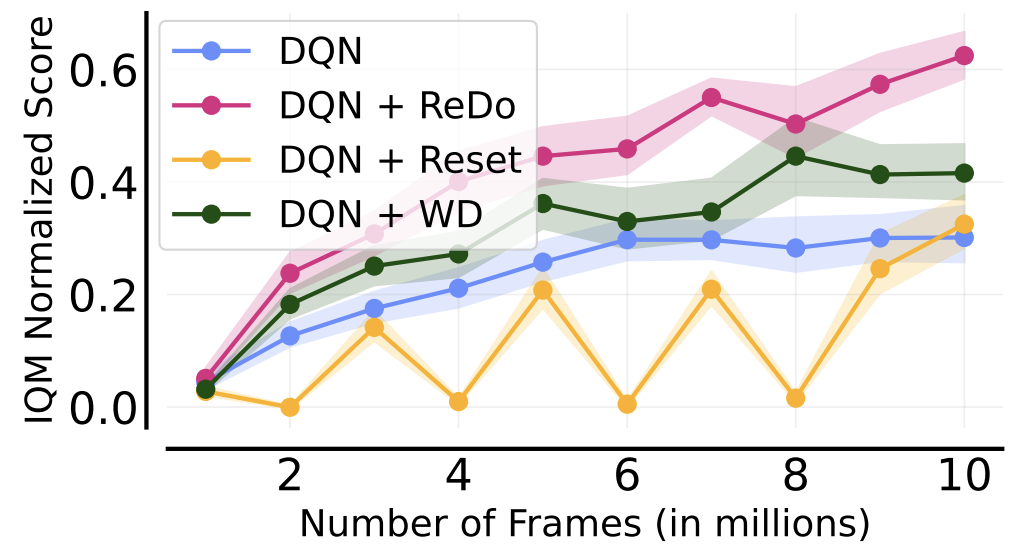
We identify the dormant neuron phenomenon in deep reinforcement learning, where an agent’s network suffers from an increasing number of inactive neurons, thereby affecting network expressivity.
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro*, Utku Evci*
This blogpost is a summary of our ICML 2023 paper. The code is available here. Many more results and analyses are available in the paper, so I encouraged you to check it out if interested!
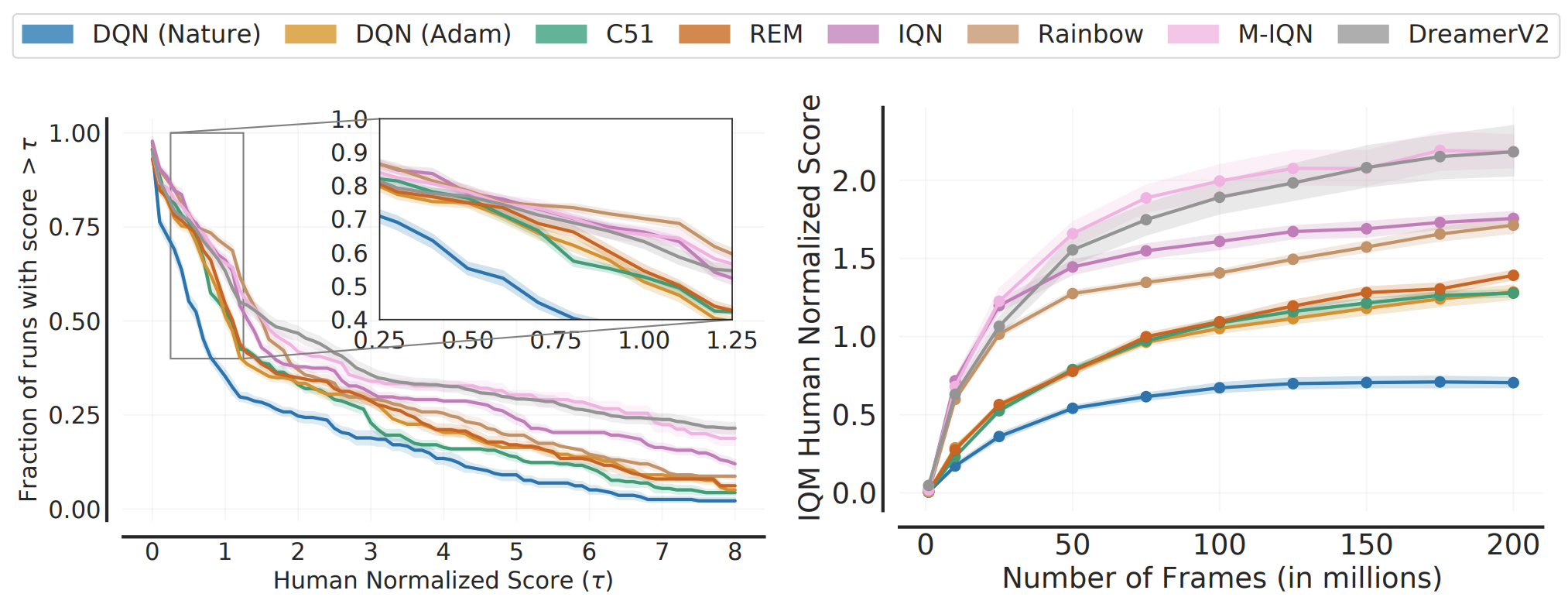
The following figure gives a nice summary of the overall findings of our work (we are reporting the Interquantile Mean (IQM) as introduced in our Statistical Precipice NeurIPS'21 paper):


PongDay
I learned on the radio that last November 29th marked the 50th anniversary of the classic arcade game Pong. This game is particularly meaningful for those of us that do RL research, as it is one of the games that is part of the Arcade Learning Environment, one of the most popular benchmarks. Pong is probably the easiest game of the whole suite, so we often use it as a test to make sure our agents are learning. Learning curves below are for agents trained with the Dopamine framework.
Introducción a los Transformers
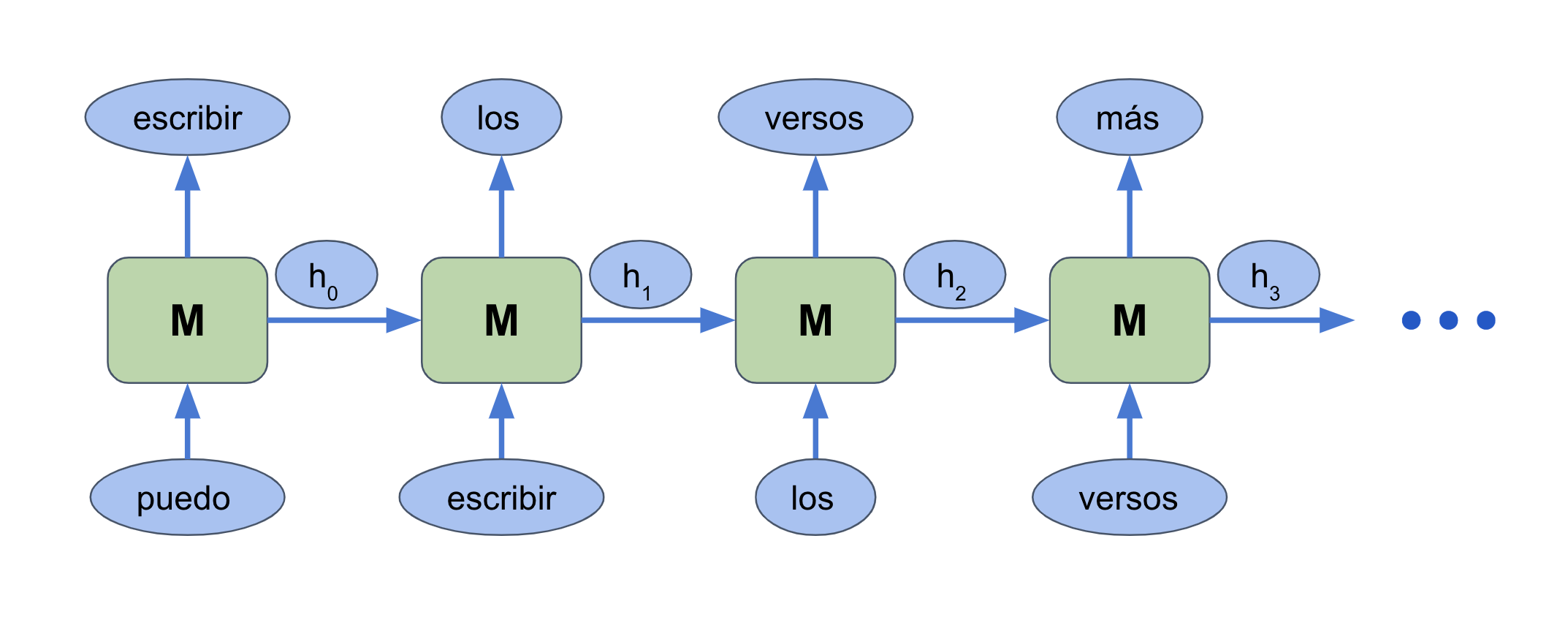
Como parte de la RIIAA en Quito, di una introducción a los Transformers, que es la arquitectura detrás de avances como GPT-3, Music Transformer, Parti, y muchos otros.
Grabación
Pueden ver la grabación aquí:
Materiales
Aquí pueden acceder a los diferentes materiales que mencioné durante el curso:
- Las diapositivas que usé en el curso
- Write with Transformers de Hugging Face (GPT-2)
- Eleuther GPT-J-6B, que es mucho mejor modelo que el GPT-2 de Hugging Face
- El colab simple sobre bigrams
- El colab de Flax sobre LSTMs
- El excelente the Illustrated Transformer de Jay Alammar, en el cual basé la descripción de Transformers.
- The Annotated Transformer
- El blog post de Parti

Th State of Spars Train ng in D ep Re nforc m nt Le rn ng
We perform a systematic investigation into applying a number of existing sparse training techniques on a variety of deep RL agents and environments, and conclude by suggesting promising avenues for improving the effectiveness of sparse training methods, as well as for advancing their use in DRL.
Laura Graesser*, Utku Evci*, Erich Elsen, Pablo Samuel Castro
This blogpost is a summary of our ICML 2022 paper. The code is available here. Many more results and analyses are available in the paper, so I encouraged you to check it out if interested!

Crosswords: A General Intelligence Challenge?
I have become obsessed with crossword puzzles, specifically the NYT crosswords, since my friend Ralph Crewe gently forced me to start doing them. Although I’m not still at his level, I’ve been working on them daily and getting noticeably better.
In doing so I’ve come to realize they are a fantastic mechanism for testing generally capable problem-solving, and in this post would like to explain the various types of challenges they present. I’ll be using past NYT crossword puzzles as examples (they’re all at least a week old so should hopefully not be spoilers for anyone).

yovoy
What is a palindrome?
A palindrome is a phrase that reads the same way from left to right, and right to left. The rules are that all characters must be used in both directions, but punctuation, capitalization, and spaces can be ignored.
¡Las mismas reglas en español!
Some well-known Palindromes:
A man, a plan, a canal, Panama!
Do geese see god?
Yo, banana boy!
Unos palíndromos en español:

CME is A-OK
The thread I wrote at the start of perf season at Google seemed to resonate with lots of people, so I decided to put a slightly extended version of it in blog-post form.
What is perf?
In brief, “perf” season at Google is when we evaluate our performance over the last few months, in the form of a self-assessment, and our peers provide their assessments on how they perceive our performance. The general purpose of this exercise is to receive feedback on how to grow as an engineer/researcher/employee, but it is also the process through which you can get promoted (by nominating yourself).