I was born and raised in Quito, Ecuador, and moved to Montreal after high school to study at McGill. I stayed in Montreal for the next 10 years, finished my bachelors, worked at a flight simulator company, and then eventually obtained my masters and PhD at McGill, focusing on Reinforcement Learning under the supervision of Doina Precup and Prakash Panangaden. After my PhD I did a 10-month postdoc in Paris before moving to Pittsburgh to join Google. I have worked at Google since 2012, and am currently a senior staff research scientist in Google DeepMind in Montreal, focusing on fundamental Reinforcement Learning research, and also being a regular advocate for increasing the LatinX representation in the research community. I am also an adjunct professor at Université de Montréal (but not currently taking any new students). Aside from my interest in coding/AI/math, I am an active musician and love running (6 marathons so far, including Boston!). If you would like to chat with me, book some time in my public office hours.

This post is based on a talk I gave at the AutoRL workshop in ICML 2024, which unfortunately was not recorded.
Reinforcement Learning (RL) has been used successfully in a number of challenging tasks, such as beating world champions at Go, controlling tokamak plasmas for nuclear fusion, optimized chip placement, and controlling stratospheric balloons. All these successes have leveraged years of research and expertise and, importantly, rely on the combination of RL algorithms with deep neural networks (as proposed in the seminal DQN paper).

This is a post based on a talk I gave a few times in 2023. I had been meaning to put it in blog post form for over a year but kept putting it off… I guess better late than never. I think some of the ideas still hold, so hope some of you find it useful!
In the seminal DQN paper, Mnih et al. demonstrated that reinforcement learning, when combined with neural networks as function approximators, could learn to play Atari 2600 games at superhuman levels. The DQN agent learned to do this over 200 million environment frames, which is roughly equivalent to 1000 hours of human gameplay…
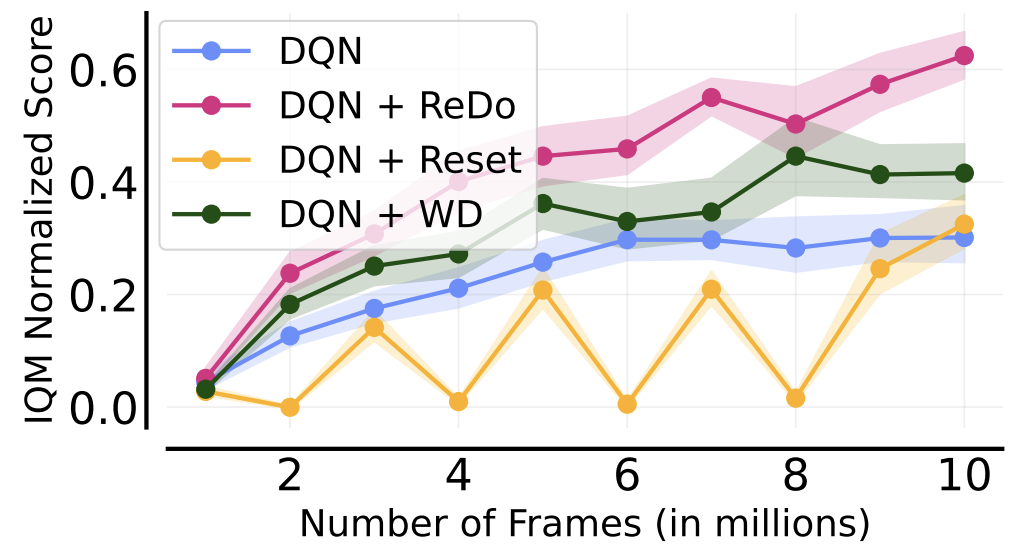
We identify the dormant neuron phenomenon in deep reinforcement learning, where an agent’s network suffers from an increasing number of inactive neurons, thereby affecting network expressivity.
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro*, Utku Evci*
This blogpost is a summary of our ICML 2023 paper. The code is available here. Many more results and analyses are available in the paper, so I encouraged you to check it out if interested!
The following figure gives a nice summary of the overall findings of our work (we are reporting the Interquantile Mean (IQM) as introduced in our Statistical Precipice NeurIPS'21 paper):
